編碼方案
數據壓縮過程稱為編碼
數據解壓過程稱為解碼
給定的字符集C
(
等長編碼方案將給定字符集C中每個字符的碼長定為[lg|C|]
【例】設待壓縮的數據文件共有
(
變長編碼方案將頻度高的字符編碼設置短
【例】設待壓縮的數據文件共有
表
字符 a b c d e f
頻度(單位
定長編碼
變長編碼
根據計算公式
(
整個文件被編碼為
注意
變長編碼可能使解碼產生二義性
【例】設E
對字符集進行編碼時
注意
等長編碼是前綴碼
平均碼長或文件總長最小的前綴編碼稱為最優的前綴碼
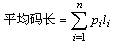
其中
pi為第i個字符得概率
li為碼長
【例】若將表
根據最優二叉樹構造哈夫曼編碼
利用哈夫曼樹很容易求出給定字符集及其概率(或頻度)分布的最優前綴碼
(
(
由哈夫曼樹求得編碼為最優前綴碼的原因
① 每個葉子字符ci的碼長恰為從根到該葉子的路徑長度li
② 樹中沒有一片葉子是另一葉子的祖先
(
給定字符集的哈夫曼樹生成後
注意
① 由於生成的編碼與要求的編碼反序
② 當某字符編碼完成時
③ 因為字符集大小為n
(
typedef struct {
char ch
char bits[n+
}CodeNode
typedef CodeNode HuffmanCode[n]
void CharSetHuffmanEncoding(HuffmanTree T
{//根據哈夫曼樹T求哈夫曼編碼表H
int c
char cd[n+
int start
cd[n]=
for(i=
H[i]
start=n
c=i
while((p=T[c]
//若T[c]是T[p]的左孩子
cd[
c=p
}
strcpy(H[i]
}//endfor
}//CharSetHuffmanEncoding
文件的編碼和解碼
有了字符集的哈夫曼編碼表之後
對壓縮後的數據文件進行解碼則必須借助於哈夫曼樹T
文件的編碼和解碼算法【參見練習】
From:http://tw.wingwit.com/Article/program/sjjg/201311/22941.html