Oracle 發布了 PL/SQL 和 Java 應用編程接口 (API) 後市場上才會推出可利用這一新發布的 API 的點擊工具或構建器這一般是最好的做法利用這一實踐開發人員可將新功能即刻融入其應用程序中以使其企業從中獲益
然而開發可利用新發布 API 的專門工具需要投入大量精力因此理想情況下從 API 發布直至推出利用該 API 的直觀最終用戶工具至少需要數個月而實際上這一滯後時間通常為一年或兩年同時利用 API 可能需要企業使用自己的工具或更為常見的是利用即席解決方案例如在報表生成器和電子表格中嵌入對 API 的調用
一種常用方法是將 API 包裝在數個腳本中然後使用自定義按鈕和菜單從電子表格訪問這些腳本但是這一方法的主要缺點在於如今的電子表格是將單個單元格中的文本和數字作為值來進行處理的因此它通常不是處理新功能的合適工具
本文將介紹如何快速將分析和其他 API 整合至一個最終用戶可從其中輕松訪問新代碼的電子表格平台作為指導性示例其中還將闡釋了如何將Oracle 數據挖掘(PL/SQL) API 重新打包為 Java API以及如何從電子表格調用的 J Cells 訪問該 APIJ Cells 完全以 Oracle JDeveloper 編寫它不僅可以將文本和數字作為單元格的值而且還可將 Java 對象作為值進行處理並可從其單元格直接訪問任何 Java API以即刻進行部署
電子表格平台
我使用的是電子表格界面只是其中允許用戶在單元格中創建任何 Java 對象以及使用基元 Java 類型每個單元格都可用作另一個單元格的變量用戶可以選擇在單元格中直接編寫 Java 代碼或使用其他格式將電子表格界面和對象(而不僅是常規電子表格中的數字和文本)使用相結合是自動進行的J Cells 為每個適合單元格的對象計算指示值這一指示值給予用戶有關顯示對象的充足線索此外還會實施一個完整的值系統可根據需要(例如當用戶雙擊給定單元格時)以各種其他格式顯示對象即使在電子表格中因為公式可能定義比較復雜所以系統還需識別要創建的對象是否具有相關的向導向導通常是一個特定於某個對象類型的圖形化代碼生成器稍後本文示例將說明如何在 J Cells 中使用向導
圖 顯示了本文示例的電子表格界面
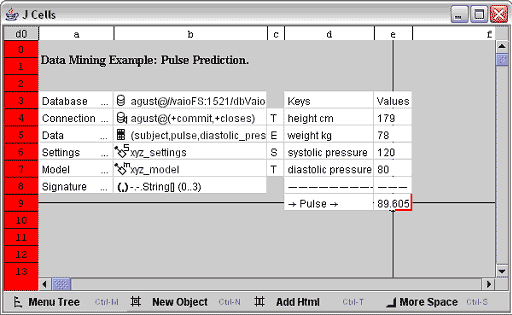
圖 J Cells 的電子表格界面
數據挖掘 API
Oracle 支持兩種兼容的 API 以訪問數據庫中的數據挖掘功能第一種是 PL/SQL API其中包括 DBMS_DATA_MINING 程序包另一種也是 Java API稱為 Oracle 數據挖掘 Java API因為 J Cells 目前最適合訪問 Java API所以需要以可直接從 Java 對其進行訪問的方式打包 PL/SQL API兩個主要的 Oracle 數據挖掘概念是設置和模型設置概念基本圍繞帶有兩列(setting_name 和 setting_value)的設置表構建;其中 setting_name 是挖掘算法使用的屬性名而 setting_value 是與該屬性相對應的值
DBMS_DATA_MINING 程序包包含若干過程包括 CREATE_MODEL 和 APPLYCREATE_MODEL 過程根據設置表(作為過程的參數之一提供)中的值為給定挖掘函數和數據集創建挖掘模型該過程簡單且易於使用實際上由用戶來為要創建的模型要使用的挖掘函數包含要使用的數據的表要建模的列以及設置表提供名稱這一方法的優點在於所有不同算法都可以類似的方法調用每種算法的微調都整合至設置表中但在很多情況下各種設置系數可由算法本身自動決定設置表中條目的復雜性根據用戶的專業技術背景和算法而有所不同許多專業用戶可能希望手動設置所有可能的系數而我們中的多數人更可能樂意系統自動給出適用設置Oracle 提供了一個要用作設置鍵的常量列表以及命名為常量或數字間隔的值
表 algo_name(算法名)設置鍵的值
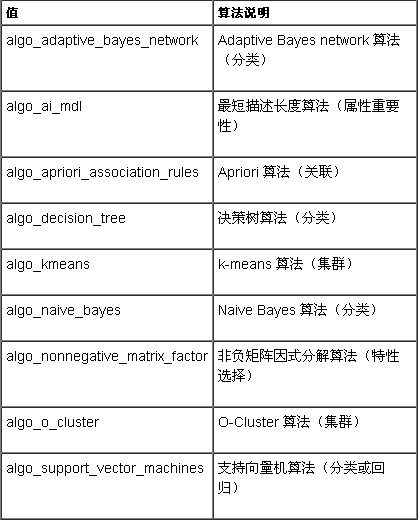
Oracle 的算法名 (algo_name) 鍵的常量值如上所示對於其中的每一個值使用了可能鍵和值的不同集等以下(圖 )顯示了向導函數是如何將這些鍵映射到樹結構並允許用戶通過操縱該設置樹定義設置表的
作為 Oracle 數據庫中創建的挖掘模型DBMS_DATA_MININGAPPLY 過程用於將該模型應用到新數據集而且這是一個易於使用的過程要求只輸入挖掘模型名包含新數據集的表名用於識別新數據集中行的列以及結果數據集名Java 類 OracleMiningModel (below) 在調用預測評分或 apply 方法時都會利用該 APPLY 過程此外DBMS_DATA_MINING 程序包包含若干根據類型將各個模型詳細信息作為結果集或以 XML 格式返回的函數這些細節函數也可通過使用 OracleMiningModel 類的實例(代表數據庫中的不同模型)進行訪問
此處可通過創建一個稱為 OracleModelSettings 的 Java 類以 Java 打包 (PL/SQL) 設置概念該類具有靈活的構造函數和各種簽名包括
public OracleModelSettings ( String modelSettingsName
Connection databaseConnection
String[] keyToValueStringMap)
throws SQLException
keyToValueStringMap 只是表單 > 的字符串數組該數組詳細說明了設置表的行以及負責在數據庫中維護設置表的類
類似地此處也可通過創建一個稱為 OracleMiningModel 的 Java 類以 Java 打包模型概念該類具有構造函數和各種簽名包括
public OracleMiningModel ( String modelName
OracleModelSettings oms
String[] keyToValueStringMap)
boolean recreate)
throws SQLException
此處使用 keyToValueMappings 數組來確定在 Oracle 數據庫中創建數據挖掘模型所需的算法以及其他命名屬性
該類的用途就是創建和維護數據挖掘模型
此外
OracleMiningModel 類還定義了用於檢索以及將該模型應用到新數據集的方法
這些方法包括以下各項
此處只顯示了一小部分
public OracleResultSet infoAprioriAssociationRules(int topn)
public OracleResultSet infoAprioriFrequentItemsets(int topn)
public OracleResultSet infoAdaptiveBayesNetwork()
public OracleResultSet infoAIMinimumDescLength()
public OracleResultSet infoKMeans()
public OracleResultSet infoNaiveBayes()
public OracleResultSet infoNonnegativeMatrixFactorization()
public OracleResultSet infoOCluster()
public OracleResultSet infoSupportVectorMachines()
public XMLType infoDecisionTree()
public Object getPrediction(String[] signature double[] doubleVal)
public HashMap score(String[] signature double[] doubleVal)
public OracleResultSet apply( String dataTable
String caseID
String resultTable
String schema
boolean overwrite)
除了具有上述簽名外所有的方法可能都會引發 SQL 意外一旦可以從兩個簡單類來管理數據挖掘功能後就可調用該電子表格平台來訪問任何可用的數據挖掘算法以在 Oracle 數據庫中建模數據集
數據挖掘示例
因此來看一個在該系統中編寫的小數據挖掘模型該模型可通過訪問 Oracle 數據庫創建並運行 ODM (Oracle Data Mining) 回歸模型該回歸模型的用途是根據輸入(例如血壓高度和體重)預測心率使用 J Cells 可直接訪問 Java API 以實例化對象並在對象上調用方法首先連接至 Oracle 數據庫DataSource 對象可通過將以下公式
() = ~ OracleDataSource(agustagustdbVaiovaioFS);
輸入到電子表格的單元格 b 中進行實例化Tilde 符號 (~) 表示縮寫符號允許 J Cells 將(右側)語句轉換為構造函數tnew cellOracleDataSource( agust agust dbVaio vaioFS);使系統能夠以用戶agust的身份訪問服務器vaioFS上的數據庫dbVaio
現在可通過在 DataSource 對象上調用正確的方法(例如在單元格 b 和 b 中分別輸入以下公式)獲得數據庫連接以及檢查數據庫中的源數據
(*) = bgetConnection();
(*) = bquery(select * from pulse_clinical);
第一個語句將向單元格 b 中返回一個 javasqlConnection 對象第二個語句將向單元格 b 中返回一個 javasqlResultSet 對象只需通過雙擊單元格 (b) 就可檢查結果集該操作會將結果表顯示在表格框架中以便查看
迄今為止我只在該電子表格中創建了幾個簡單的數據對象現在可以調用數據挖掘 API 來定義一個設置對象然後創建一個簡單的數據挖掘模型首先通過在單元格 b 中輸入以下語句來創建一個設置對象
(*) = new cellodmOracleModelSettings(xyz_settings b
new String[]{
algo_name > algo_support_vector_machines
svms_kernel_function > svms_linear} );
立刻我發現該公式中的問題是最終用戶友好的
因此
注冊一個帶有 J Cells 的向導
在提示用戶後自動生成該公式
可能是個不錯的辦法
一般
電子表格在用戶創建復雜公式時都會給予幫助
因此用戶可以期望在實例化對象時獲得指導
部署的向導如圖 所示
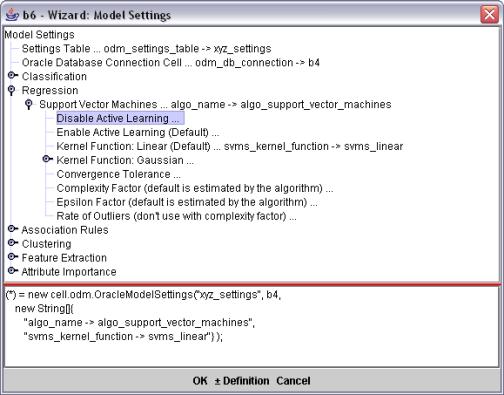
圖 典型的向導界面
同樣數據挖掘模型通過使用向導或輸入公式來創建在這兩種情況中結果模型都是在直接指定 API 調用的單元格 b 中進行實例化
(*)= new cellodmOracleMiningModel(xyz_model b
new String[]{
data_table_name > pulse_clinical
mining_function > regression
target_column_name > pulse
case_id_column_name > subject}
false );
使用該公式結果實例化數據挖掘模型將在 Oracle 數據庫中生成標准的 Oracle 數據挖掘模型
該模型可通過雙擊單元格 b
進行查看
模型的完整值如圖
所示
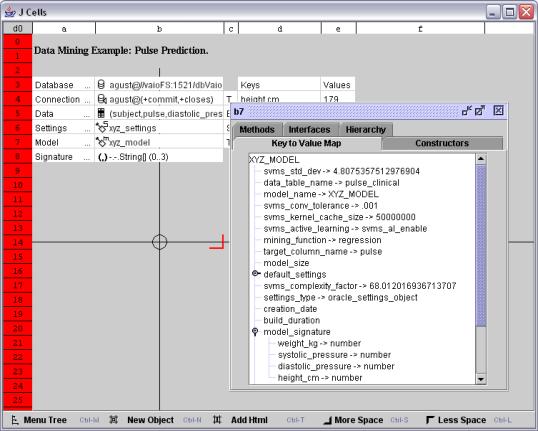
圖 查看單元格 b 中的模型
使用上述的 OracleMiningModel 方法可將該模型應用到 Oracle 數據庫中的數據集作為一個簡單的交互式評分模型(一般適用於電子表格應用程序)用戶可能希望輸入血壓高度和體重值讓數據庫使用剛才定義的模型預測心率這個在模型對象上定義的 Java API 方法 getPrediction 非常適合這一用途在單元格 eee 以及 e 中(以單元格 b 中簽名數組指定的順序)鍵入輸入值後通過輸入以下公式可進行評分
(*) = bgetPrediction(bnew double[]{eeee});
同樣該公式將直接訪問 Java API 以獲取並在單元格 e 中顯示評分結果如圖 所示
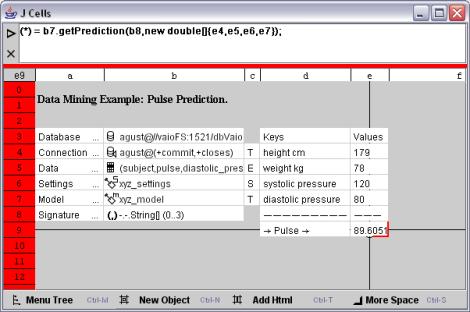
圖 將模型應用到輸入值
電子表格優點
電子表格在最終用戶之間的流行多少有些令人費解一方面當今最常用的電子表格系統長期以來令許多開發人員氣餒他們習慣於更為靈活強大的系統而另一方面對於非開發人員而言使用電子表格系統具有以下一些明顯優點無須構建圖形化用戶界面單獨構建和測試每個公式(代碼)以及隱藏公式看到的是更為簡單的計算結果這些優點只存在於當今流行的電子表格中使用公式可將數字或文本返回到單元格而許多系統主要受限於此此處演示了如何移除這一限制並創建更為強大的工具然後用它來直接訪問 Oracle 的數據挖掘模型功能以及其他 API
結論
通過利用更為強大的電子表格可以顯著縮短向最終用戶引入新技術版本(例如由發布的 Java API 和 PL/SQL API)的時間事實上使用此處的方法直接將原始 Java API 交給非編程人員以立即整合至決策制定流程或進行預測和分析是切實可行的
From:http://tw.wingwit.com/Article/program/Oracle/201311/17437.html