Oracle 使用平衡樹(Btree)存儲索引以便提升數據訪問速度當不使用索引時用戶必須對數據進行順序掃描(sequential scan)來查找指定的值如果有 n 行數據那麼平均需要掃描的行為 n/因此當數據量增長時這種方法的開銷將顯著增長
如果將一個已排序的值列(list of the values)劃分為多個區間(range)每個區間的末尾包含指向下個區間的指針(pointer)而搜索樹(search tree)中則保存指向每個區間的指針此時在 n 行數據中查詢一個值所需的時間為 log(n)這就是 Oracle 索引的基本原理
下圖顯示了平衡樹索引(Btree index)的結構
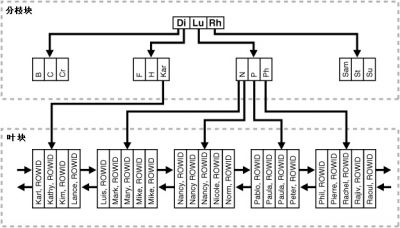
在一個平衡樹索引(Btree index)中最底層的索引塊(葉塊(leaf block))存儲了被索引的數據值以及對應的 rowid葉塊之間以雙向鏈表的形式相互連接位於葉塊之上的索引塊被稱為分支塊分枝塊中包含了指向下層索引塊的指針如果被索引的列存儲的是字符數據那麼索引值為這些字符數據在當前數據庫字符集中的二進制值
對於唯一索引每個索引值對應著唯一的一個 rowid對於非唯一索引每個索引值對應著多個已排序的 rowid因此在非唯一索引中索引數據是按照索引鍵(index key)及 rowid 共同排序的鍵值(key value)全部為 NULL 的行不會被索引只有位圖索引(bitmap index)和簇索引(cluster index)例外在數據表中如果兩個數據行的全部鍵值都為 NULL也不會與唯一索引相沖突
有兩種類型的索引塊
用於搜索的分支塊(branch block)
用於存儲索引數據的葉塊(leaf block)
分支塊中存儲以下信息
最小的鍵值前綴用於在(本塊的)兩個鍵值之間做出分支選擇
指向包含所查找鍵值的子塊的指針
包含 n 個鍵值的分支塊含有 n+ 個指針鍵值及指針的數量同時還受索引塊容量的限制
所有葉塊相對於其根分支塊的深度是相同的
葉塊用於存儲以下信息
數據行的鍵值(key value)
鍵值對應數據行的 ROWID
所有的 鍵值ROWID 對都與其左右的兄弟節點向鏈接並按照(keyROWID)的順序排序
平衡樹數據結構(Btree structure)具有以下優勢
平衡樹(Btree)內所有葉塊的深度相同因此獲取索引內任何位置的數據所需的時間大致相同
平衡樹索引(Btree index)能夠自動保持平
平衡樹內的所有塊的使用容量平均在塊總容量的 / 左右
在大區間范圍內進行查詢時無論匹配個別值還是搜索一個區間平衡樹都能提供較好的查詢性能
數據插入(insert)更新(update)及刪除(delete)的效率較高且易於維護鍵值的順序
大型表小型表利用平衡樹進行搜索的效率都較好且搜索效率不會因數據增長而降低
From:http://tw.wingwit.com/Article/program/Oracle/201311/16672.html