運行基准測試並分析結果
一旦准備就緒就可以著手基准測試收集和分析數據了
通常來說自動化基准測試是個好主意這樣做可以獲得更精確的測試結果因為自動化的過程可以防止測試人員偶爾遺漏某些步驟或者誤操作另外也有助於歸檔整個測試過程
自動化的方式有很多可以是一個Makefile 文件或者一組腳本腳本語言可以根據需要選擇shellPHPPerl 等都可以要盡可能地使所有測試過程都自動化包括裝載數據系統預熱執行測試記錄結果等
一旦設置了正確的自動化操作基准測試將成為一步式操作如果只是針對某些應用做一次性的快速驗證測試可能就沒必要做自動化但只要未來可能會引用到測試結果建議都盡量地自動化否則到時候可能就搞不清楚是如何獲得這個結果的也不記得采用了什麼參數這樣就很難再通過測試重現結果了
基准測試通常需要運行多次具體需要運行多少次要看對結果的記分方式以及測試的重要程度要提高測試的准確度就需要多運行幾次一般在測試的實踐中可以取最好的結果值或者所有結果的平均值亦或從五個測試結果裡取最好三個值的平均值可以根據需要更進一步精確化測試結果還可以對結果使用統計方法確定置信區間(confidence interval)等不過通常來說不會用到這種程度的確定性結果注只要測試的結果能滿足目前的需求簡單地運行幾輪測試看看結果的變化就可以了如果結果變化很大可以再多運行幾次或者運行更長的時間這樣都可以獲得更確定的結果
獲得測試結果後還需要對結果進行分析也就是說要把數字變成知識最終的目的是回答在設計測試時的問題理想情況下可以獲得諸如升級到 核CPU 可以在保持響應時間不變的情況下獲得超過% 的吞吐量增長或者增加索引可以使查詢更快的結論如果需要更加科學化建議在測試前讀讀null hypothesis 一書但大部分情況下不會要求做這麼嚴格的基准測試
如何從數據中抽象出有意義的結果依賴於如何收集數據通常需要寫一些腳本來分析數據這不僅能減輕分析的工作量而且和自動化基准測試一樣可以重復運行並易於文檔化下面是一個非常簡單的shell 腳本演示了如何從前面的數據采集腳本采集到的數據中抽取時間維度信息腳本的輸入參數是采集到的數據文件的名字

假設該腳本名為analyze當前面的腳本生成狀態文件以後就可以運行該腳本可能會得到如下的結果
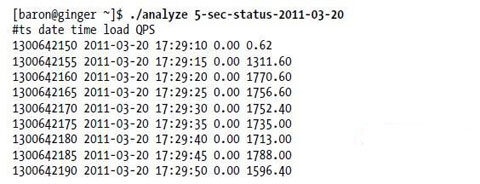
第一行是列的名字第二行的數據應該忽略因為這是測試實際啟動前的數據接下來的行包含Unix 時間戳日期時間(注意時間數據是每 秒更新一次前面腳本說明時曾提過)系統負載數據庫的QPS(每秒查詢次數)五列這應該是用於分析系統性能的最少數據需求了接下來將演示如何根據這些數據快速地繪成圖形並分析基准測試過程中發生了什麼
返回目錄高性能MySQL
編輯推薦
ASP NET開發培訓視頻教程
數據倉庫與數據挖掘培訓視頻教程
Oracle索引技術
From:http://tw.wingwit.com/Article/program/MySQL/201311/29735.html