一個診斷案例()
在本節中我們將逐步演示一個客戶實際碰到的間歇性性能問題的診斷過程這個案例的診斷需要具備MySQLInnoDB 和GNU/Linux 的相關知識但這不是我們要討論的重點要嘗試從瘋狂中找到條理閱讀本節並保持對之前的假設和猜測的關注保持對之前基於合理性和基於可度量的方式的關注等等我們在這裡深入研究一個具體和詳細的案例為的是找到一個簡單的一般性的方法
在嘗試解決其他人提出的問題之前先要明確兩件事情並且最好能夠記錄下來以免遺漏或者遺忘
首先問題是什麼?一定要清晰地描述出來費力去解決一個錯誤的問題是常有的事在這個案例中用戶抱怨說每隔一兩天服務器就會拒絕連接報max_connections 錯誤這種情況一般會持續幾秒到幾分鐘發生的時間非常隨機
其次為解決問題已經做過什麼操作?在這個案例中用戶沒有為這個問題做過任何操作這個信息非常有幫助因為很少有其他事情會像另外一個人來描述一件事情發生的確切順序和曾做過的改變及其後果一樣難以理解(尤其是他們還是在經過幾個不眠之夜後滿嘴咖啡味道地在電話裡絕望吶喊的時候)如果一台服務器遭受過未知的變更產生了未知的結果問題就更難解決了尤其是時間又非常有限的時候
搞清楚這兩個問題後就可以開始了不僅需要去了解服務器的行為也需要花點時間去梳理一下服務器的狀態參數配置以及軟硬件環境使用ptsummary 和ptmysqlsummary 工具可以獲得這些信息簡單地說這個例子中的服務器有 個CPU 核心GB 內存數據量有MB且全部采用InnoDB 引擎存儲在一塊SSD 固態硬盤上服務器的操作系統是GNU/LinuxMySQL 版本使用的存儲引擎版本是InnoDBplugin 之前我們已經為這個客戶解決過一些異常問題所以對其系統已經比較了解過去數據庫從來沒有出過問題大多數問題都是由於應用程序的不良行為導致的初步檢查了服務器也沒有發現明顯的問題查詢有一些優化的空間但大多數情況下響應時間都不到 毫秒所以我們認為正常情況下數據庫服務器運行良好(這一點比較重要因為很多問題一開始只是零星地出現慢慢地累積成大問題比如RAID 陣列中壞了一塊硬盤這種情況)
這個案例研究可能有點乏味這裡我們不厭其煩地展示所有的診斷數據解釋所有的細節對幾個不同的可能性深入進去追查原因在實際工作中其實不會對每個問題都采用這樣緩慢而冗長的方式也不推薦大家這樣做這裡只是為了更好地演示案例而已
我們安裝好診斷工具在Threads_connected 上設置觸發條件正常情況下Threads_connected 的值一般都少於但在發生問題時該值可能飙升到幾百下面我們會先給出一個樣本數據的收集結果後續再來評論首先試試看你能否從大量的輸出中找出問題的重點在哪裡

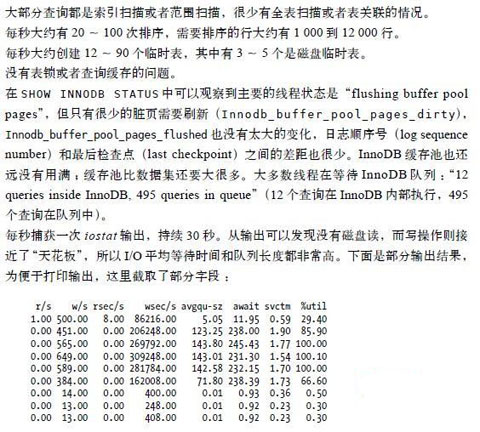
vmstar的輸出也驗證了iostat的結果並且CPU的大部分時間是空閒的只是偶爾在寫尖峰時有一些I/O等待時間(最高約占%的CPU)是不是感覺腦袋裡塞滿了東西?當你深入一個系統的細節並且沒有任何先入為主(或者故意忽略了)的觀念時很容易碰到這種情況最終只能檢查所有可能的情況很多被檢查的地方最終要麼是完全正常的要麼發現是問題導致的結果而不是問題產生的原因盡管此時我們會有很多關於問題原因的猜測但還是需要繼續檢查下面給出的oprofile報表並且在給出更多數據的時候添加一些評論和解釋
samples % image name app name symbol name
novmlinux novmlinux /novmlinux
mysqld mysqld /usr/libexec/mysqld
libcso libcso memcpy
ha_innodbso ha_innodbso build_template()
ha_innodbso ha_innodbso btr_search_guess_on_hash
ha_innodbso ha_innodbso row_sel_store_mysql_rec
ha_innodbso ha_innodbso rec_init_offsets_comp_ordinary
ha_innodbso ha_innodbso row_search_for_mysql
ha_innodbso ha_innodbso rec_get_offsets_func
ha_innodbso ha_innodbso cmp_dtuple_rec_with_match
返回目錄高性能MySQL
編輯推薦
ASP NET開發培訓視頻教程
數據倉庫與數據挖掘培訓視頻教程
Oracle索引技術
From:http://tw.wingwit.com/Article/program/MySQL/201311/29697.html