散列方法不同於順序查找二分查找二叉排序樹及B樹上的查找它不以關鍵字的比較為基本操作采用直接尋址技術在理想情況下無須任何比較就可以找到待查關鍵字查找的期望時間為O()
散列表的概念
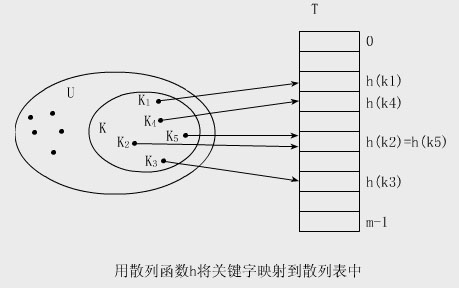
散列表
設所有可能出現的關鍵字集合記為U(簡稱全集)實際發生(即實際存儲)的關鍵字集合記為K(|K|比|U|小得多)
散列方法是使用函數h將U映射到表T[m]的下標上(m=O(|U|))這樣以U中關鍵字為自變量以h為函數的運算結果就是相
應結點的存儲地址從而達到在O()時間內就可完成查找
其中
① hU→{…m} 通常稱h為散列函數(Hash Function)散列函數h的作用是壓縮待處理的下標范圍使待處理
的|U|個值減少到m個值從而降低空間開銷
② T為散列表(Hash Table)
③ h(K i )(K i ∈U)是關鍵字為K i 結點存儲地址(亦稱散列值或散列地址)
④ 將結點按其關鍵字的散列地址存儲到散列表中的過程稱為散列(Hashing)
散列表的沖突現象
()沖突
兩個不同的關鍵字由於散列函數值相同因而被映射到同一表位置上該現象稱為沖突(Collision)或碰撞發生沖突的兩個
關鍵字稱為該散列函數的同義詞(Synonym)
【例】上圖中的k ≠k 但h(k )=h(k )故k 和K 所在的結點的存儲地址相同
()安全避免沖突的條件
最理想的解決沖突的方法是安全避免沖突要做到這一點必須滿足兩個條件
①其一是|U|≤m
②其二是選擇合適的散列函數
這只適用於|U|較小且關鍵字均事先已知的情況此時經過精心設計散列函數h有可能完全避免沖突
()沖突不可能完全避免
通常情況下h是一個壓縮映像雖然|K|≤m但|U|>m故無論怎樣設計h也不可能完全避免沖突因此只能在設計h時盡可
能使沖突最少同時還需要確定解決沖突的方法使發生沖突的同義詞能夠存儲到表中
()影響沖突的因素
沖突的頻繁程度除了與h相關外還與表的填滿程度相關
設m和n分別表示表長和表中填人的結點數則將α=n/m定義為散列表的裝填因子(Load Factor)α越大表越滿沖突的機會
也越大通常取α≤
From:http://tw.wingwit.com/Article/program/sjjg/201311/23740.html