一單項選擇題(本大題共小題每小題分共分)
在每小題列出的四個備選項中只有一個是符合題目要求的請將其代碼填寫在題後的括號內錯選多選或未選均無分
若將數據結構形式定義為二元組(KR)其中K是數據元素的有限集合則R是K上( )
A 操作的有限集合 B 映象的有限集合
C 類型的有限集合 D 關系的有限集合
在長度為n的順序表中刪除第i個元素(≤i≤n)時元素移動的次數為( )
A ni+ B i
C i+ D ni
若不帶頭結點的單鏈表的頭指針為head則該鏈表為空的判定條件是( )
A head==NULL B head>next==NULL
C head!=NULL D head>next==head
引起循環隊列隊頭位置發生變化的操作是( )
A 出隊 B 入隊
C 取隊頭元素 D 取隊尾元素
若進棧序列為且進棧和出棧可以穿插進行則不可能出現的出棧序列是( )
A B
C D
字符串通常采用的兩種存儲方式是( )
A 散列存儲和索引存儲 B 索引存儲和鏈式存儲
C 順序存儲和鏈式存儲 D 散列存儲和順序存儲
設主串長為n模式串長為m(m≤n)則在匹配失敗情況下樸素匹配算法進行的無效位移次數為( )
A m B nm
C nm+ D n
二維數組A[][]采用列優先的存儲方法若每個元素各占個存儲單元且第個元素的地址為則元素A[][]的地址為( )
A B
C D
對廣義表L=((ab)(cd)(ef))執行操作tail(tail(L))的結果是( )
A (ef) B ((ef))
C (f) D ( )
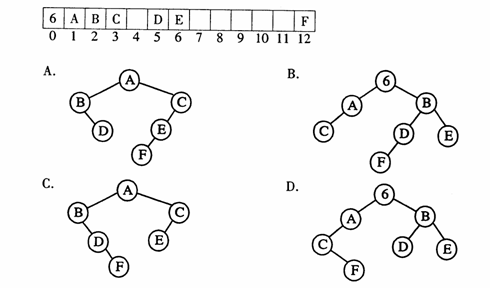
下列圖示的順序存儲結構表示的二叉樹是( )
n個頂點的強連通圖中至少含有( )
A n條有向邊 B n條有向邊
C n(n)/條有向邊 D n(n)條有向邊
對關鍵字序列()進行增量為的一趟希爾排序的結果為 ( )
A () B )
C () D ()
若在階B樹中插入關鍵字引起結點分裂則該結點在插入前含有的關鍵字個數為( )
A B
C D
由同一關鍵字集合構造的各棵二叉排序樹( )
A 其形態不一定相同但平均查找長度相同
B 其形態不一定相同平均查找長度也不一定相同
C 其形態均相同但平均查找長度不一定相同
D 其形態均相同平均查找長度也都相同
ISAM文件和VSAM文件的區別之一是( )
A 前者是索引順序文件後者是索引非順序文件
B 前者只能進行順序存取後者只能進行隨機存取
C 前者建立靜態索引結構後者建立動態索引結構
D 前者的存儲介質是磁盤後者的存儲介質不是磁盤
二填空題(本大題共小題每空分共分)
數據的邏輯結構在計算機存儲器內的表示稱為數據的____________
刪除雙向循環鏈表中*p的前驅結點(存在)應執行的語句是____________
棧下溢是指在____________時進行出棧操作
已知substr(silen)函數的功能是返回串s中第i個字符開始長度為len的子串strlen(s)函數的功能是返回串s的長度若s=″ABCDEFGHIJK″t=″ABCD″執行運算substr(sstrlen(t) strlen(t))後的返回值為____________
去除廣義表LS=(aaa……an)中第個元素由其余元素構成的廣義表稱為LS的____________
已知完全二叉樹T的第層只有個結點則該樹共有____________個葉子結點
在有向圖中以頂點v為終點的邊的數目稱為v的____________
當關鍵字的取值范圍是實數集合時無法進行箱排序和____________排序
產生沖突現象的兩個關鍵字稱為該散列函數的____________
假設散列文件中一個桶能存放m個記錄則桶溢出的含義是當需要插入新的記錄時該桶中____________
三解答題(本大題共小題每小題分共分)
假設以數組seqn[m]存放循環隊列的元素設變量rear和quelen分別指示循環隊列中隊尾元素的位置和元素的個數
()寫出隊滿的條件表達式;
()寫出隊空的條件表達式;
()設m=rear=quelen=求隊頭元素的位置;
()寫出一般情況下隊頭元素位置的表達式
()
()
()
()
已知一棵二叉樹的中序序列為ABCDEFG層序序列為BAFEGCD請畫出該二叉樹
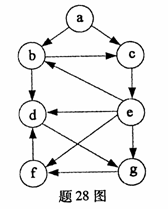
畫出下圖所示有向圖的所有強連通分量
對個關鍵字進行快速排序在最好的情況下僅需進行次關鍵字的比較
()假設關鍵字集合為{}試舉出能達到上述結果的初始關鍵字序列;
()對所舉序列進行快速排序寫出排序過程
()
()
四算法閱讀題(本大題共小題每小題分共分)
閱讀下列算法並回答問題
()設順序表L=()寫出執行f(&L)之後的L;
()設順序表L=()寫出執行f(&L)之後的L;
()簡述算法的功能
void f(SeqList*L DataType x)
{
int i = j;
while (ilength && x>L>data[i])i++;
if(ilength && x==L>data[i])
{
for(j=i+;jlength;j++)
L>data[j]=L>data[j];
L>length;
}
else
{
for(j=L>length;j>i;j)
L>data[j]=L>data[j];
L>data[i]=x;
L>length++;
}
}
()
()
()
已知圖的鄰接表表示的形式說明如下
#define MaxNum //圖的最大頂點數
typedef struct node {
int adjvex; //鄰接點域
struct node *next; //鏈指針域
} EdgeNode; //邊表結點結構描述
typedef struct {
char vertex; //頂點域
EdgeNode *firstedge; //邊表頭指針
} VertexNode; //頂點表結點結構描述
typedef struct {
VertexNode adjlist[MaxNum]; //鄰接表
int n e; //圖中當前的頂點數和邊數
} ALGraph; //鄰接表結構描述
下列算法輸出圖G的深度優先生成樹(或森林)的邊閱讀算法並在空缺處填入合適的內容使其成為一個完整的算法
typedef enum {FALSE TRUE} Boolean;
Boolean visited[MaxNum];
void DFSForest(ALGraph *G){
int i;
for(i=;in;i++)
visited[i]=___________________();
for(i=;in;i++) if (!visited[i]) DFSTree(Gi);
}
void DFSTree(ALGraph *G int i) {
EdgeNode *p;
visited[i]=TRUE;
p=G>adjlist[i] firstedge;
while(p!=NULL){
if(!visited[p>adjvex]){
printf(″
From:http://tw.wingwit.com/Article/program/sjjg/201311/23395.html