算法分析
.評價算法好壞的標准
求解同一計算問題可能有許多不同的算法究竟如何來評價這些算法的好壞以便從中選出較好的算法呢?
選用的算法首先應該是正確的此外主要考慮如下三點
① 執行算法所耗費的時間
② 執行算法所耗費的存儲空間其中主要考慮輔助存儲空間
③ 算法應易於理解易於編碼易於調試等等
.算法性能選擇
一個占存儲空間小運行時間短其它性能也好的算法是很難做到的原因是上述要求有時相互抵觸要節約算法的執行時間往往要以犧牲更多的空間為代價而為了節省空間可能要耗費更多的計算時間因此我們只能根據具體情況有所側重
① 若該程序使用次數較少則力求算法簡明易懂
② 對於反復多次使用的程序應盡可能選用快速的算法
③ 若待解決的問題數據量極大機器的存儲空間較小則相應算法主要考慮如何節省空間
.算法的時間性能分析
()算法耗費的時間和語句頻度
一個算法所耗費的時間=算法中每條語句的執行時間之和
每條語句的執行時間=語句的執行次數(即頻度(Frequency Count))×語句執行一次所需時間
算法轉換為程序後每條語句執行一次所需的時間取決於機器的指令性能速度以及編譯所產生的代碼質量等難以確定的因素
若要獨立於機器的軟硬件系統來分析算法的時間耗費則設每條語句執行一次所需的時間均是單位時間一個算法的時間耗費就是該算法中所有語句的頻度之和
【例】求兩個n階方陣的乘積 C=A×B其算法如下:
# define n // n 可根據需要定義這裡假定為
void MatrixMultiply(int A[a]int B [n][n]int C[n][n])
{ //右邊列為各語句的頻度
int i j k;
() for(i=; i<n;j++) n+
() for (j=;j<n;j++) { n(n+)
() C[i][j]=; n
() for (k=; k<n; k++) n(n+)
() C[i][j]=C[i][j]+A[i][k]*B[k][j]; n
}
}
該算法中所有語句的頻度之和(即算法的時間耗費)為
T(n)=n+n+n+ ()
分析
語句()的循環控制變量i要增加到n測試到i=n成立才會終止故它的頻度是n+但是它的循環體卻只能執行n次語句()作為語句()循環體內的語句應該執行n次但語句()本身要執行n+次所以語句()的頻度是n(n+)同理可得語句()()和()的頻度分別是nn(n+)和n
算法MatrixMultiply的時間耗費T(n)是矩陣階數n的函數
()問題規模和算法的時間復雜度
算法求解問題的輸入量稱為問題的規模(Size)一般用一個整數表示
【例.】矩陣乘積問題的規模是矩陣的階數
【例.】一個圖論問題的規模則是圖中的頂點數或邊數
一個算法的時間復雜度(Time Complexity 也稱時間復雜性)T(n)是該算法的時間耗費是該算法所求解問題規模n的函數當問題的規模n趨向無窮大時時間復雜度T(n)的數量級(階)稱為算法的漸進時間復雜度
【例.】算法MatrixMultidy的時間復雜度T(n)如()式所示當n趨向無窮大時顯然有
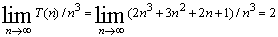
這表明當n充分大時T(n)和n之比是一個不等於零的常數即T(n)和n是同階的或者說T(n)和n的數量級相同記作T(n)=(n)是算法MatrixMultiply的漸近時間復雜度
數學符號的嚴格的數學定義
若T(n)和f(n)是定義在正整數集合上的兩個函數則T(n)=(f(n))表示存在正的常數C和n使得當n≥n時都滿足≤T(n)≤C·f(n)
()漸進時間復雜度評價算法時間性能
主要用算法時間復雜度的數量級(即算法的漸近時間復雜度)評價一個算法的時間性能
【例.】有兩個算法A和A求解同一問題時間復雜度分別是T(n)=nT(n)=n
()當輸入量n<時有T(n)>T(n)後者花費的時間較少
()隨著問題規模n的增大兩個算法的時間開銷之比n/n=n/亦隨著增大即當問題規模較大時算法A比算法A要有效地多
它們的漸近時間復雜度(n)和(n)從宏觀上評價了這兩個算法在時間方面的質量在算法分析時往往對算法的時間復雜度和漸近時間復雜度不予區分而經常是將漸近時間復雜度T(n)=O(f(n))簡稱為時間復雜度其中的f(n)一般是算法中頻度最大的語句頻度
【例.】算法MatrixMultiply的時間復雜度一般為T(n)=(n)f(n)=n是該算法中語句()的頻度下面再舉例說明如何求算法的時間復雜度
【例.】交換i和j的內容
Temp=i;
i=j;
j=temp;
以上三條單個語句的頻度均為該程序段的執行時間是一個與問題規模n無關的常數算法的時間復雜度為常數階記作T(n)=O()
如果算法的執行時間不隨著問題規模n的增加而增長即使算法中有上千條語句其執行時間也不過是一個較大的常數此類算法的時間復雜度是O()
【例.】變量計數之一
() x=;y=;
() for(k;k<=n;k++)
() x++;
() for(i=;i<=n;i++)
() for(j=;j<=n;j++)
() y++;
一般情況下對步進循環語句只需考慮循環體中語句的執行次數忽略該語句中步長加終值判別控制轉移等成分因此以上程序段中頻度最大的語句是()其頻度為f(n)=n所以該程序段的時間復雜度為T(n)=(n)
當有若干個循環語句時算法的時間復雜度是由嵌套層數最多的循環語句中最內層語句的頻度f(n)決定的
【例.】變量計數之二
() x=;
() for(i=;i<=n;i++)
() for(j=;j<=i;j++)
() for(k=;k<=j;k++)
() x++;
該程序段中頻度最大的語句是()內循環的執行次數雖然與問題規模n沒有直接關系但是卻與外層循環的變量取值有關而最外層循環的次數直接與n有關因此可以從內層循環向外層分析語句()的執行次數
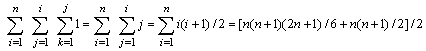
則該程序段的時間復雜度為T(n)=(n/+低次項)=(n)
()算法的時間復雜度不僅僅依賴於問題的規模還與輸入實例的初始狀態有關
【例.】在數值A[n]中查找給定值K的算法大致如下
()i=n;
()while(i>=&&(A[i]!=k))
() i;
()return i;
此算法中的語句()的頻度不僅與問題規模n有關還與輸入實例中A的各元素取值及K的取值有關:
①若A中沒有與K相等的元素則語句()的頻度f(n)=n
②若A的最後一個元素等於K則語句()的頻度f(n)是常數
()最壞時間復雜度和平均時間復雜度
最壞情況下的時間復雜度稱最壞時間復雜度一般不特別說明討論的時間復雜度均是最壞情況下的時間復雜度
這樣做的原因是最壞情況下的時間復雜度是算法在任何輸入實例上運行時間的上界這就保證了算法的運行時間不會比任何更長
【例.】查找算法【例·】在最壞情況下的時間復雜度為T(n)=(n)它表示對於任何輸入實例該算法的運行時間不可能大於(n)
平均時間復雜度是指所有可能的輸入實例均以等概率出現的情況下算法的期望運行時間
常見的時間復雜度按數量級遞增排列依次為常數()對數階(logn)線形階(n)線形對數階(nlogn)平方階(n)立方階(n)…k次方階(nk)指數階(n)顯然時間復雜度為指數階(n)的算法效率極低當n值稍大時就無法應用
類似於時間復雜度的討論一個算法的空間復雜度(Space Complexity)S(n)定義為該算法所耗費的存儲空間它也是問題規模n的函數漸近空間復雜度也常常簡稱為空間復雜度算法的時間復雜度和空間復雜度合稱為算法的復雜度
From:http://tw.wingwit.com/Article/program/sjjg/201311/22593.html