簡介 由於拼寫錯誤
截斷
缺少或插入的標記
空字段
意外的縮略語和其他不規則問題
實際的數據是
有問題
的
因此
在數據倉庫項目中
很大一部分的時間和金錢都花費在了提取
轉換和加載 (ETL) 階段
在 ETL 階段
新數據被清理
標准化
並使其與現有數據一致
在 Microsoft SQL Server?
中可用的模糊查找和模糊分組轉換
有助於使 ETL 過程在遇到若干種在實際數據中觀測到的常見錯誤時更易復原
它們解決一般的匹配和分組問題
而無需特定於域的規則和腳本的專家集合
通過為您的域自定義模糊查找和模糊分組
您可以利用數據轉換服務 (Data Transformation Services
DTS) 設計器內的通用數據清理算法
並避免創建復雜的自定義規則和代碼
模糊查找使得您能夠將輸入記錄與引用表中的無錯的
標准化的記錄匹配
匹配過程對於在輸入記錄中存在的錯誤有復原功能
模糊查找返回最相近的匹配並指出匹配的質量
例如
由於輸入數據中的錄入錯誤或其他錯誤
在一次新的銷售交易中輸入的客戶信息(名稱和地址)可能與包含所有當前客戶的客戶引用表中的任何記錄都不完全匹配
即使不存在完全匹配
模糊查找也會從客戶引用表返回最佳匹配記錄
並提供度量值以表明匹配質量
模糊分組使您能夠標識一個表中的記錄的組 — 在這個表中每個組都可能對應相同的實際實體
分組對在實際數據中觀測到的常見錯誤有復原功能
因為每組中的記錄可能彼此不相同但彼此很相似
例如
對於將一個客戶引用表中描述每個實際客戶的所有記錄歸類到一起
模糊分組是很有用的
模糊查找和模糊分組為復雜的
常遇到的數據清理問題提供易用的解決方案
盡管它們與現有的諸如 soundex
基於規則的系統
基於編輯距離的系統及全文搜索等現有方法有一些聯系
但是模糊查找和模糊分組有一些優勢
模糊查找和模糊分組使用一個自定義的
考慮編輯距離(例如
hits
與
bit
的距離為
)
標記數
標記順序以及相對頻率的獨立於域的距離函數
結果
與全文搜索相比
模糊查找和模糊分組獲得的辨別力要精細得多
因為它們捕獲了更詳細的數據結構
由於它們完全是標記驅動的
模糊查找和模糊分組不像 soundex 那樣有依賴於語言的組件
因為它們不只使用編輯距離
模糊查找和模糊分組不容易被變換誤導
而且與只使用編輯距離的方法相比
能夠檢測出更高級的模式
模糊查找和模糊分組緊密集成在 DTS 中
這使它們對 SQL Server
的 ETL 任務來說易於使用
而且無需或只需很少的自定義編程
下面的部分提供了使用並了解模糊查找和模糊分組的分步指南
並且包括了這些轉換的一些實現和性能方面的內容
這對用戶來說很有用
本文意在通過更詳細地解釋模糊查找和模糊分組的某些方面來補充在線書籍
有關更多關於選項和配置參數方面的信息
請參閱在線書籍項
這些項包括的信息有
列寬
層次結構
標記處理選項以及其他有用的參數
這些參數提供一些方法
以加入可用來提高某些方案的准確性的域知識
模糊查找入門 模糊查找可以通過使用損壞的或不完整的字符串關鍵字查找大型表中的數據
例如
如果您想要按名稱和地址查找客戶信息
您可以使用模糊查找來查找這些信息
即使您的輸入與您的引用表中所存儲的記錄並不完全匹配
用於模糊查找的最簡單的包是由包含一個源
一個模糊查找轉換和一個目標的單個 DTS 數據流任務組成(圖
)
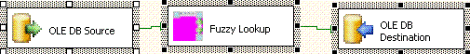 圖 最簡單的模糊查找包
圖 最簡單的模糊查找包 要構造最簡單的模糊查找包
打開 DTS 設計器
創建一個新的 ETL 項目
添加一個新包
單擊 Data Flow 選項卡
然後接受 add a data flow 項選項
在數據流圖上
從 Toolbox 拖動 OLE DB 源和目標轉換
然後通過使用一個模糊查找的實例連接它們
通過選擇一個連接和包含有問題的數據的輸入表
將 OLE DB 源指向您的新數據
您的數據必須包含一些字符串列
雙擊 Fuzzy Lookup 打開自定義用戶界面 (UI)
從 Reference table name 下拉菜單選擇您希望轉換的連接和表
指向已經存儲的引用數據
在 Columns 選項卡上
將您想要比較的項從 Available Input Columns(來自 OLE DB 源)拖動到 Available Lookup Columns(來自引用表)
例如
您可能希望將輸入中的 StreetAddress 與引用表中的 Address 相比較
為 Available Lookup Columns 中的所有項選擇復選框
然後單擊 OK
將 OLE DB 目標指向您可以為其編寫新表的連接
然後單擊 New
接受默認創建語句
現在您已經准備好運行模糊查找了
要運行您剛剛創建的包
在
解決方案資源管理器
窗口中鼠標右擊其名稱
然後選擇 Execute
DTS 設計器運行此包
並提供關於管道的詳細的可視反饋
取決於引用數據的大小
您可能會注意到在容錯索引 (Error
Tolerant Index
ETI) 創建時的延遲
ETI 是模糊查找在運行時使用的主數據結構
在 ETI 創建後
所有輸入行都被處理然後結果被寫入到目標
通過顯示由每個組件處理的行數
DTS 設計器為您提供關於管道進度的反饋
您也可以通過鼠標右擊模糊查找和 OLE DB 目標之間的連接器將一個 DataViewer 放置在管道上
這允許您實時看到那些模糊查找與您的輸入行匹配的行
除了匹配元組
模糊查找還輸出可信度和相似性百分比
有關更多關於可信度和相似性百分比的信息
請參閱本文後面的解釋結果
最有效地使用模糊查找 運行模糊查找的主要步驟是創建 ETI
執行查找和檢查輸出
下列部分提供了關於這些步驟的每一步的詳細信息
了解容錯索引 模糊查找通過索引在引用數據和引用行 ID 中出現的標記創建 ETI
如果您將 ETI 存儲在了服務器上
您可以通過從中選擇一些行來查看其內容
每個行由一個索引標記和包含該標記的引用行 ID 序列組成
在地址示例中
如果您的引用數據包含
N
E
th St
ETI 將包含
N
E
th 和St
的標記項
以下是 ETI 如何隨引用數據而增長
在引用表中有越多的唯一標記和越多的行
ETI 中就會有越多的項和越長的列表
有關更多關於 ETI 的大小如何隨引用數據而增長的信息
請參閱本文後面的了解性能
標記化過程是通過模糊查找自定義屬性 delimiter string 控制的
例如
如果您想要索引 N
E
而不是 N 和 E
則請將句點從分隔符列表刪除
結果是 N
E
作為一個單獨的標記在 ETI 中顯示
而且會在運行時作為一個單元被查找
由於分隔符的全局應用
如 First
Avenue 也作為一個單獨的標記顯示
由於 ETI 的構造成本因引用數據大小的增長而變得更加昂貴
模糊查找提供一個選項
可以將 ETI 存儲在服務器上
日後可以重新使用
這個選項使您能夠避免在每次運行模糊查找時都重新創建一個 ETI
如果您的 ETI 會花費太多的時間而不能每次運行都重建
考慮創建一次而在接下來的運行中對其進行重用
要做到這一點
在 Reference Table 選項卡上選擇 Store new index
然後指定一個表名稱
注 ETI 可能會變得相當巨大
所以規劃服務器空間可能是必要的
在最壞的情況下
ETI 可能會是引用表的索引行中的數據大小的兩倍
如果您想要存儲 ETI 但是引用數據不時地更改
您還可以啟用 Maintain stored index
這個功能在您的 ETI 上安裝一個觸發器
它檢測對基礎引用數據的修改
只要這樣的修改發生
此觸發器將相應的更改傳遞到 ETI
從而使其保持為最新
如果您不安裝表維護
對您的引用表所做的更改將在沒有警告的情況下使任何關聯的 ETI 無效
注 表維護功能在 Beta
版中不可用
在運行時發生了什麼 在運行時
模糊查找使用 ETI 查找其輸入的最佳匹配
在確定最佳匹配時
最重要的參數是 MinSimilarity 閥值
您可以通過使用模糊查找UI 來設置這個自定義屬性
引用元組只有在其與輸入足夠相似時才會被返回
因此
如果您設置了一個很高的相似性要求
模糊查找考慮的候選也會較少
而且結果可能是不返回任何匹配
如果您將 MinSimilarity 設置得低
模糊查找將考慮更多的候選
而更有可能找到一個匹配
但搜索可能會用去更長的時間
匹配條件包括 為匹配給出的引用元組而需要對輸入元組做的標記或字符插入
刪除
替換以及重新排序的數量
例如
輸入
First Lane 很可能被認為比輸入
N
E
st Ln & Leary Way 更接近引用
First Ln
來自引用表的標記頻率
非常頻繁的標記通常被認為幾乎不會提供對匹配有用的信息
相對稀少的標記被認為是它們在其中出現的行的特性
設置正確的閥值取決於您的應用程序和數據的性質
如果您要求一個在您的輸入和引用之間的相近的匹配
您應該考慮為 MinSimilarity 設置一個大值
如
如果您在進行一個研究性的項目
您可能會對檢查弱匹配與相近匹配一樣感興趣
那麼您應該將 MinSimilarity 設置為一個較低的值
如
並沒有可以用於確定這個范圍的固定規則
所以建議您對數據設置進行試驗
查看幾次運行的輸出可以供設置最優值考慮
例如
您執行第一次運行使用的閥值為
您觀測到一個特定的輸入與一個相似性為
的特定的輸出匹配
如果對於您的應用程序來說此元組過於不相似(詳細信息請參閱解釋結果)
第二次運行您可以將 MinSimilarity 設置為
從而排除與其過於不相似的匹配
在一個小的測
From:http://tw.wingwit.com/Article/program/SQLServer/201311/22133.html