PGA的概念以及所包含的內存結構作為一個復雜的oracle數據庫系統來說
每時每刻都要處理不同的用戶所提交的SQL語句
獲取數
據並返回數據給用戶
眾所周知
解析SQL語句的工作是在oracle實例中的shared pool所完成的
那麼對於每個session來說
其執行SQL語句時所傳入的綁定變量放在哪裡?而且
對於那些需要執行比較復雜SQL的session來說
比如需要進行排序(sort)或hash連接(hash
join)時
這時這些session所需要的內存空間又從哪裡來?另外
還有與每個session相關的一些管理控制信息又放在哪裡?對於諸如此類與每個session相關的一些內存的分配問題
oracle通過引入PGA這個內存組件來進行解決
PGA的相關概念 PGA按照oracle官方文檔解釋
叫做程序全局區(Program Global Area)
但也有些資料上說還可以理解為進程全局區(Process Global Area)
這兩者沒有本質的區別
它首先是一個內存區域
其次
該區域中包含了與某個特定服務器進程相關的數據和控制信息
每個進程都具有自己私有的PGA區
這也就意味著
這塊區域只能被其所屬的進程進入
而不能被其他進程訪問
所以在PGA中不需要latch這樣的內存結構來保護其中的信息
籠統的來說
PGA裡包含了當前進程所使用的有關操作系統資源的信息(比如打開的文件句柄等)以及一些與當前進程相關的一些私有的狀態信息
每個PGA區都包含兩部分
固定PGA部分(Fixed PGA)
這部分包含一些小的固定尺寸的變量
以及指向變化PGA部分的指針
變化PGA部分(Variable PGA)
這部分是按照堆(Heap)來進行組織的
所以這部分也叫做PGA堆
可以從X$KSMPP視圖中看到有關PGA堆的分布信息
PGA堆中所包含的內存結構包括
有關一些固定表的永久性內存
如果session使用的是專用連接方式(dedicated server)
則還含有用戶全局區(UGA-User Global Area)子堆
如果session使用的是共享連接方式(shared server)
則UGA位於SGA中
調用全局區(CGA-Call Global Area)子堆
UGA(用戶全局區)的相關概念 UGA是包含與某個特定session相關信息的內存區域
比如session的登錄信息以及session私有的SQL區域等
每個UGA也包含兩個部分
固定UGA部分(Fixed UGA)
這部分包含一些小的固定尺寸的變量
以及指向變化UGA部分的指針
變化UGA部分(Variable UGA)
這部分也是按照堆來進行組織的
可以從X$KSMUP視圖中看到有關UGA堆的分布情況
UGA堆的分布與OPEN_CURSORS
OPEN_LINKS等參數有關系
所謂的游標(cursor)就是放在這裡的
UGA堆中所包含的內存結構包括
私有SQL區域(Private SQL Area)
這部分區域包含綁定變量信息以及運行時的內存結構等數據
每一個發出SQL語句的session都有自己的私有SQL區域
這部分區域又可分成兩部分
永久內存區域
這裡存放了相同SQL語句多次執行時都需要的一些游標信息
比如綁定變量信息
數據類型轉換信息等
這部分內存只有在游標被關閉時才會被釋放
運行時區域
這裡存放了當SQL語句運行時所使用的一些信息
這部分區域的大小尺寸依賴於所要執行的SQL語句的類型(sort或hash
join等)和復雜度以及所要處理的數據行的行數以及行的大小
在處理SQL語句時的第一步就是要創建運行時區域
對於DML(INSERT
UPDATE
DELETE)語句來說
SQL語句執行完畢就釋放該區域
而對於查詢語句(SELECT)來說
則是在所有數據行都被獲取並傳遞給用戶以後被釋放
或者該查詢被取消以後也會被釋放
Session相關的信息
這部分信息包括
正在使用的包(package)的狀態信息
使用alter session這樣的命令所啟用的跟蹤信息
或者所修改的session級別的優化器參數(optimizer_mode)
排序參數(sort_area_size等)
修改的NLS參數等
所打開的dblinks
可使用的角色(roles)等
從上面可以很明顯的看出
我們最需要關注的就是私有SQL區域中的運行時區域了
實際上
從
i
以後
對這部分區域有了一個新的名稱
SQL工作區域(SQL Work Area)
SQL工作區域的大小依賴於所要處理的SQL語句的復雜程度而定
如果SQL語句包含諸如group by
Hash
join等這樣的操作
則會需要很大的SQL工作區域
實際上
我們調整PGA也就是調整這塊區域
後面還會說到這部分內容
而UGA所處的位置完全由session連接的方式決定
如果session是通過共享服務器(shared server)方式連到數據庫的
則毫無疑問
UGA必須能夠被所有進程訪問
所以這個時候UGA是從SGA中進行分配的
進一步說
如果SGA中設置了large pool
則UGA從large pool裡進行分配
否則
如果沒有設置large pool
則UGA只能從shared pool裡進行分配了
如果session是通過專用服務器(dedicated server)方式連到數據庫的
則UGA是從進程的PGA中進行分配的
CGA(調用全局區)的相關概念 CGA也是一塊內存區域
但它是動態的
隨著調用(call)的開始而創建
在調用過程中一直存在
直到調用結束時被釋放
它存放的是在調用過程中所需要的數據
我們知道
調用主要包括解析(parse)調用
執行(executive)調用
獲取(fetch)調用以及遞歸SQL調用和PL/SQL調用
從調用的種類可以看出
實際上在調用過程中所需要的數據
比如SQL AREA
PL/SQL AREA和SORT AREA基本都是放在UGA中的
因為這些數據在各個調用之間必須一直存在並可用
而在CGA中只存放了在調用過程中臨時需要的數據
比如直接I/O緩存(Direct I/O Buffer)以及堆棧空間等數據結構
因此
沒有CGA中的數據結構
調用是無法完成的
注意
CGA不象UGA可以位於SGA中(以共享服務器模式連接)
CGA一定是位於PGA中的
如果當前進程正在運行
則每個PGA中只有一個CGA
如果當前進程沒有運行
則該進程的PGA中就沒有CGA
轉儲PGA
就象實例中的其他內存結構一樣oracle同樣提供了可以將PGA轉儲到跟蹤文件的方法方法如下
SQL> alter session set events immediate trace name heapdump level n;
其中的level n決定了將哪些內存堆轉儲到跟蹤文件
Level : PGA匯總信息
Level : SGA匯總信息
Level : UGA匯總信息
Level : 當前調用的匯總信息(CGA)
Level : 用戶調用的匯總信息(CGA)
Level : Large pool的匯總信息(LGA)
Level : PGA詳細信息
Level : SGA詳細信息
Level : UGA 詳細信息
Level : 當前調用的詳細信息
Level : 用戶調用的詳細信息
Level : Large pool的詳細信息
舉例來說我們轉儲PGA的匯總信息
SQL> alter session set events immediate trace name heapdump level ;
到user_dump_dest所定義的目錄下找到跟蹤文件並打開可以看到類似下面的信息
******************************************************
HEAP DUMP heap name=pga heap desc=DB
extent sz=xc alt= het= rec= flg= opc=
parent= owner= nex= xsz=xc
EXTENT addr=
Chunk c sz= perm perm alo=
EXTENT addr=BCC
Chunk bc sz= freeable Fixed Uga
EXTENT addr=BC
Chunk b sz= perm perm alo=
Chunk af sz= free
Chunk bac sz= freeable kopolal dvoid
……………
Chunk ec sz= recreate Alloc environm latch=
ds eade sz= ct=
Chunk eabc sz= freeable kpuinit env han
我們可以看到其中的紅色部分就是在PGA中所包含的固定UGA部分同時我們可以使用如下的命令將PGA的子堆也給轉儲出來其中以前使用
SQL> alter session set events immediate trace name heapdump_addr level n;
以後使用
SQL> alter session set events immediate trace name heapdump_addr level addr n;
其中的n表示子堆的地址而子堆的地址可以在PGA的轉儲文件中找到比如上面的例子中我們可以看到這樣的一行
ds eade sz= ct=
這裡的ds eade就是某個子堆的地址這是個十六進制的數值於是我們先將其轉換為十進制數值
SQL> select to_number(eadexxxxxxxx) from dual;
TO_NUMBER(EADEXXXXXXXX)
這裡的就是轉儲PGA子堆的命令中的n所以我們可以執行(我的測試庫為)
SQL> ALTER SESSION SET EVENTS immediate trace name heapdump_addr level addr ;
PGA自動管理及深入研究
PGA自動管理概述
在i之前我們主要是通過設置sort_area_sizehash_area_size等參數值(通常都叫做*_area_size)來管理PGA的使用不過嚴格說來是對PGA中的UGA中的私有SQL區域進行管理這塊內存區域又有個名稱叫做SQL工作區域但是這裡有個問題就是這些參數都是針對某個session而言的也就是說設置的參數值對所有連進來的session都生效在數據庫實際運行過程中總有些session需要的PGA多而有些session需要的PGA少如果都設置一個很小的*_area_size則會使得某些SQL語句運行時由於需要將臨時數據交換到磁盤而導致效率低下而如果都設置一個很大的值又有可能一方面浪費空間另一方面消耗過多內存可能導致操作系統其他組件所需要的內存短缺而引起數據庫整體性能下降所以如何設置*_area_size的值一直都是DBA很頭疼的一個問題
而從i起所引入的一個新的特性可以有效的解決這個問題這個特性就是自動PGA管理DBA可以根據數據庫的負載情況估計所有session大概需要消耗的PGA的內存總和然後把該值設置為初始化參數pga_aggregate_target的值即可Oracle會按照每個session的需要為其分配PGA同時會盡量維持整個PGA的內存總和不超過該參數所定義的值這樣的話oracle就能盡量避免整個PGA的內存容量異常增長而影響整個數據庫的性能從而就有效的解決了設置*_area_size所帶來的問題
不過遺憾的是i下的PGA自動管理只對專用連接方式有效對共享連接方式無效g以後對兩種連接方式都有效
啟用PGA自動管理是很容易的只要設置兩個初始化參數即可首先設置workarea_size_policy參數該參數為auto(也是缺省值)時表示啟用PGA自動管理而設置該參數為manual時則表示禁用PGA自動管理仍然沿用i之前的方式即使用*_area_size對PGA進行管理其次就是設置pga_aggregate_target了該參數可以動態進行調整范圍是從MB到GB – 個字節
PGA自動管理深入
PGA中對性能影響最大的就是SQL工作區了通常說來SQL工作區越大則對於SQL語句的執行的效率就高從而對於用戶的響應時間就越少理想情況下SQL工作區應該可以容納SQL執行過程中所涉及到的所有輸入數據和控制信息當然這只是理想情況現實往往總是不能盡如人意很多情況下SQL工作區是不能容納執行SQL所需要的內存空間的從而不得不交換到臨時表空間裡為了衡量執行SQL所需要的內存與實際分配給該SQL的SQL工作區之間的契合程度oracle將所分配的SQL工作區大小分成三種類型
optimal尺寸SQL語句能夠完全在所分配的SQL工作區內完成所有的操作這時的性能最佳
onepass尺寸SQL語句需要與磁盤上的臨時表空間交互一次才能夠在所分配的SQL工作區中完成所有的操作 multipass尺寸由於SQL工作區過小從而導致SQL語句需要與磁盤上的臨時表空間交互多次才能完成所有的操作這個時候的性能將急劇下降
當系統整體負載不大時oracle傾向於為每個session的PGA分配optimal尺寸大小的SQL工作區
而隨著負載上升比如連接的session逐漸增多導致同時執行的SQL語句越來越多時oracle就會傾向於為每個session的PGA分配onepass尺寸大小的SQL工作區甚至是multipass尺寸的SQL工作區了
那麼PGA自動管理機制在內部到底是如何實現的呢?很遺憾oracle官方並沒有給出說明文檔其實這本身也說明了PGA自動管理的內部算法會隨著版本升級而發生變化不過知其然而不知其所以然總是會讓諸如我等之類的技術人員感覺如梗在喉還好曾經就有一些專門做oracle優化的公司發布的文檔中介紹了PGA內部的實現原理我想這可能是oracle公司透露給這些公司的這裡就做些簡單的介紹不過記住這裡所描述的PGA自動管理的原理並不一定就是將來版本的原理只能說是截至到的PGA自動管理的原理
PGA自動管理是采用名為循環反饋(feedback loop)的算法來實現的如下圖所示
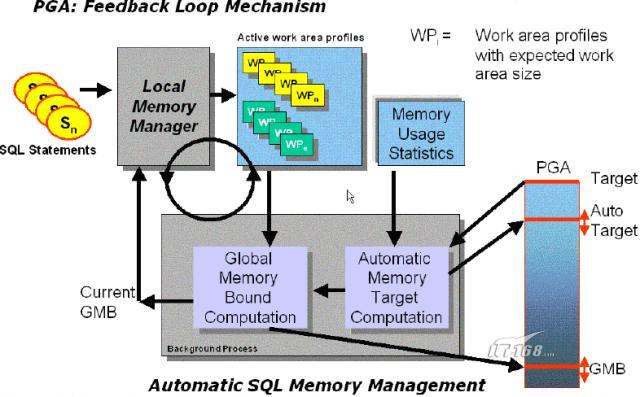
上圖中當開始處理一條SQL時oracle會使用本地內存管理器(local memory manager)對該SQL語句相關的work area profile進行注冊work area profile是一組元數據描述了該SQL語句所需要的工作區的所有特征包括該SQL的類型(sort還是hashjoin等)該SQL語句的並行度所需要的內存等信息它是SQL語句操作與內存管理器之間唯一的接口當SQL語句執行完畢時其對應的work area profile就會被刪除而在SQL語句執行期間為了反映SQL語句當前已經消耗的內存以及是否被交換到臨時表空間了等狀態信息oracle會不斷更新其對應的work area profile所以說SQL語句的work area profile是有生命周期的始終能夠體現其對應SQL語句的工作區狀態因此我們可以說在任何時間點所有當前活動的work area profile就能夠基本體現當前所有session對PGA內存的需要以及當前正在使用的PGA內存通過查詢視圖v$sql_workarea_active可以顯示所有當前活動的work area profile的相關信息
現在我們需要引入另外一個後台守護進程(background daemon)叫做全局內存管理器(global memory manager)這個進程每隔秒會啟動一次每次啟動時都會根據當前所有活動的work area profile的數量以及其他相關信息計算出這個時候的SQL工作區的內存限度(memory bound)也就是每個工作區最大盡量不能超過多大(不過注意嚴格說來應該是盡量不超過實際上這個最大值是可以被超過的後面會用個實例來說明)然後立即發布這個內存限度
最後本地內存管理器關閉反饋循環並根據當前的內存限度以及當前work area profile從而計算出當前SQL工作區應該具有的內存大小並為進程分配該大小的內存以執行SQL語句這個內存的大小尺寸就叫做期望尺寸(expect size)可以從v$sql_workarea_active的expected_size列看到期望尺寸的大小同時這個期望尺寸會定時更新並據此對SQL工作區進行調整
Oracle內部對這個期望尺寸的大小有如下規則的限制
期望尺寸不能小於最低的內存需求
期望尺寸不能大於optimal尺寸
如果內存限度介於最低的內存需求和optimal尺寸之間則使用內存限度作為期望尺寸的大小但是排序操作除外因為排序操作算法的限制對於分配的內存在optimal尺寸和onepass尺寸之間時排序操作不會隨著內存的增加而更快完成除非能夠為排序操作分配optimal尺寸所以如果排序操作的內存限度介於onepass尺寸和optimal尺寸之間的話期望尺寸取onepass尺寸
如果SQL以並行方式運行則期望尺寸為上面三個規則算出的值乘以並行度
非並行模式下按照通常的說法是期望尺寸不能超過min(%*pga_aggregate_targetMB)但實際上這是在不修改_pga_max_size和_smm_max_size這兩個隱藏參數的前提下可以簡單的這麼認為嚴格說來應該是不能超過min(%*pga_aggregate_target%*_pga_max_size_smm_max_size)對於並行的情況就更加復雜可以簡單認為不超過%*pga_aggregate_target
下面我們舉例(如下圖所示)來說明全局內存管理器是如何計算並應用內存限度的比如
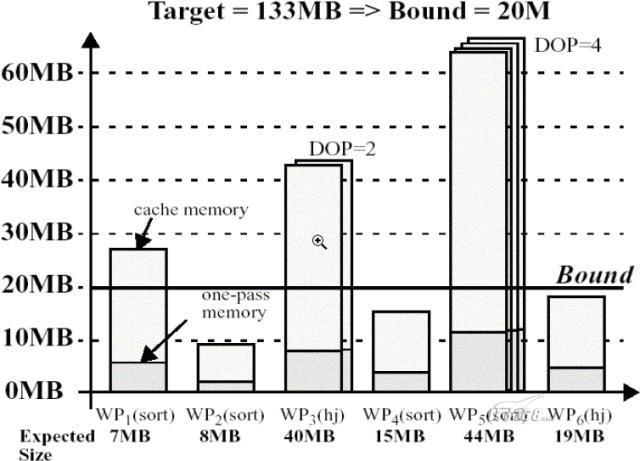
當前系統中有個活動的work area profileWP所需要的onepass內存為MB而optimal內存為MBWP是一個並行度為的hashjoin它需要MB的onepass內存以及MB的optimal的內存假設pga_aggregate_target設置為MB則可以簡單的認為全局內存管理器直接將除以也就是大約MB作為內存限度的值於是該內存限度限制了分配給WP的工作區只能為MB也就是onepass的大小因為WP是一個排序操作如果給它分配MB也不能使它在以optimal的方式完成而對於MB的內存限度WP可以分到MB的工作區因為WP的並行度為所以可以分配MB×的大小的工作區
如何設置新數據庫的PGA值
我們一旦設置了pga_aggregate_target以後所有的*_area_size就將被忽略那麼我們該如何來設置該參數的值呢?這依賴於數據庫的用途如果數據庫為OLTP(聯機事務處理)應用的則其應用一般都是小的短的進程所需要的PGA也相應較少所以該值該值通常為總共分配給oracle實例的%另外的%則給了SGA如果數據庫為OLAP(DSS)(數據倉庫或決策分析)應用的則其應用一般都是很大的運行時間很長的進程因此需要的PGA就多所以通常為PGA分配%的內存而如果數據庫為混合類型的則情況比較復雜一般會先分配%的初始值而後隨著數據庫的應用而不斷對PGA進行監控並進行相應的調整
比如對於GB物理內存的數據庫服務器來說按照oracle推薦的分配給oracle實例的內存為物理內存的%那麼對於OLTP應用來說pga_aggregate_target的值大約就是MB (( MB× %)×%)而對於OLAP來說則該值大約就是MB (MB×%)×%)
當然這裡所說的都是對於一個新的數據庫來說初始設置的值這些值並不一定正確可能設置過大也可能設置過小必須隨著系統的不斷運行DBA需要不斷監控從而對其進行調整
PGA監控及調優
我們已經大致了解了有關PGA的相關理論知識現在我們可以開始動手實踐來驗證上面的理論並
可以開始對PGA的使用進行監控以及調優了以下測試都是在windows XPoracle 以及專用連
接模式下進行的
准備測試用例
首先我們先創建一個測試用例
SQL> create table pga_test as select * from dba_objects;
SQL> select count(*) from pga_test;
COUNT(*)
然後引入幾個監控PGA的腳本
pga_by_hashvaluesql這是一個監控SQL語句所使用的SQL工作區的腳本
SELECT
bsql_text
aoperation_type
apolicy
alast_memory_used/(*) as Used MB
aestimated_optimal_size/(*) as Est Opt MB
aestimated_onepass_size/(*) as Est OnePass MB
alast_execution
alast_tempseg_size
FROM v$sql_workarea av$sql b
WHERE ahash_value = bhash_value
and ahash_value = &hashvalue
/
pga_by_sessionsql第二個腳本是pga_by_sessionsql用來監控session所使用的PGA和UGA的大小
select aname bvalue
from v$statname a v$sesstat b
where astatistic# = bstatistic#
and bsid = &sid
and aname like %ga %
order by aname
/
第三個腳本監控進程所使用的PGA的大小pga_by_processsql
SELECT
apga_used_mem PGA Used
apga_alloc_mem PGA Alloc
apga_max_mem PGA Max
FROM v$process av$session b
where aaddr = bpaddr
and bsid= &sid
/
單個session對PGA使用情況的監控
我們分別創建個session第一個session(sess#)執行測試語句第二個session(sess#)執行pga_by_hashvaluesql腳本第三個session(sess#)執行pga_by_sessionsql腳本第四個session(sess#)執行pga_by_processsql腳本第五個session(sess#)設置相關參數以下按照順序描述整個測試的過程
Sess#
SQL> select sid from v$mystat where rownum=;
SID
Sess#查詢當前sid為的session的PGA和UGA各為多少可以看到即使不執行任何的SQL只要session連接了就會消耗大約MB的PGA內存
SQL> @pga_by_sessionsql;
NAME VALUE
session pga memory
session pga memory max
session uga memory
session uga memory max
Sess#我們將pga_aggregate_target設置為MB
SQL> alter system set pga_aggregate_target=M;
Sess#執行測試語句
SQL> set autotrace traceonly stat;
SQL> select a* from pga_test apga_test b where rownum< order by ;
Sess#找到sess#中所執行的SQL語句的hash值
SQL> select hash_value from v$sql where sql_text=select a* from pga_test apga_test b where rownum< order by ;
HASH_VALUE
Sess#
SQL> @d:\pga_by_hashvaluesql
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
PASSES
我們可以看到該SQL語句所分配的工作區為MB這個值就是%*pga_aggregate_target(M*)符合前面說到的期望尺寸為min(%*pga_aggregate_targetMB)
Sess#
SQL> @ pga_by_sessionsql;
NAME VALUE
session pga memory
session pga memory max
session uga memory
session uga memory max
可以看到為了執行測試語句為該session分配的PGA為個字節其中UGA為個字節大約M同時可以看出執行完測試語句以後oracle就把該session的PGA空間回收了(PGA從下降到而UGA從下降到)順帶提一下在i中分配了PGA以後是不會回收的也就是說session pga memory始終等於session pga memory max而i以後的PGA的分配方式發生了改變從而能夠在分配PGA以後還可以再回收一部分內存結合上面為SQL語句所分配的M的工作區可以知道UGA中的其他空間占用大約M而SQL工作區占整個PGA大小大約為%從這個方面也可以看出SQL工作區是PGA中最占空間也是最重要的部分
Sess#
SQL> @d:\pga_by_processsql
輸入 sid 的值:
原值 : and bsid= &sid
新值 : and bsid=
PGA Used PGA Alloc PGA Max
可以看到這幾個視圖查出來的PGA的大小基本都是一致的
我們繼續測試從sess#可以看出如果要讓該SQL語句完全在內存中完成需要大約MB的PGA空間根據%的原理倒算可以知道這個時候的pga_aggregate_target應該大於MB(/)於是我們設置MB來看看是不是確實進行optimal了順便提醒一下並不是說你的電腦得有超過MB的物理內存你才可以設置M的pga_aggregate_target事實上pga_aggregate_target是按需分配的不象SGA一旦設置就占著內存不用也得占著也就是說是PGA是隨著對內存需求的增長而不斷增長的我測試的機器上只有GB的物理內存但做測試時完全可以將pga_aggregate_target設置GB甚至更高的GB
Sess#我們將pga_aggregate_target設置為MB
SQL> alter system set pga_aggregate_target=M;
Sess#
SQL> select a* from pga_test apga_test b where rownum< order by ;
Sess#
SQL> @d:\pga_by_hashvaluesql
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
OPTIMAL
我們可以看到該SQL語句確實完全在內存裡完成了(LAST_EXECUTION為OPTIMAL)同時實際的期望尺寸始終會小於optimal(<)也符合前面說的第二條規則
我們繼續測試看看SQL工作區的期望尺寸是否真的不能超過MB為此需要設置%*
pga_aggregate_target>MB因此pga_aggregate_target最少要大於G我們設置GB
Sess#我們將pga_aggregate_target設置為GB
SQL> alter system set pga_aggregate_target=G;
Sess#注意為了能夠占用更多的PGA這時的SQL語句已經把where條件修改了
SQL> select a* from pga_test apga_test b where rownum< order by ;
Sess#找到該語句的hash值
SQL> select hash_value from v$sql where sql_text=select a* from pga_test apga_test b where rownum< order by ;
HASH_VALUE
Sess#
SQL> /
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
PASS
可以看到optimal尺寸已經超過MB很多了但是實際分配的期望尺寸卻只有MB左右而G*為MB為何該SQL用不了呢?這其實是由兩個隱藏參數決定的分別是_pga_max_size和_smm_max_size我們來看一下這兩個參數的含義和缺省值
Sess#
SQL> select ksppinm ksppstvl ksppdesc from x$ksppi x x$ksppcv y where xindx = yindx and ksppinm in (_pga_max_size_smm_max_size);
KSPPINM KSPPSTVL KSPPDESC
_pga_max_size Maximum size of the PGA memory for one process
_smm_max_size maximum work area size in auto mode (serial)
我們可以看到_pga_max_size缺省值為M(//)而_smm_max_size缺省值為MB(上面的查詢結果中顯示的單位是KB)而每個session的PGA最多只能使用_pga_max_size的一半也就是MB
當你修改參數pga_aggregate_target的值時Oracle系統會根據pga_aggregate_target和_pga_max_size這兩個值來自動修改參數_smm_max_size具體修改的規則是
如果_pga_max_size大於%*pga_aggregate_target則_smm_max_size為%*pga_aggregate_target
如果_pga_max_size小於等於%*pga_aggregate_target則_smm_max_size為%*_pga_max_size
有些資料上說可以通過修改_pga_max_size來突破這個MB的限制真的是這樣嗎?我們來測試Sess#修改參數_pga_max_size為MB
SQL> show parameter pga
NAME TYPE VALUE
pga_aggregate_target big integer
SQL> alter system set _pga_max_size=M;
我們將_pga_max_size的值設置為M其一半就是MB已經超過%*pga_aggregate_target(即MB)了所以這兩者的較小值為M如果這時我們在sess#中再次執行測試語句應該可以使用超過MB的SQL工作區了我們來看測試結果
Sess#
SQL> select a* from pga_test apga_test b where rownum< order by ;
Sess#
SQL> /
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
PASS
我們看到期望尺寸仍然是大約MB並沒有突破MB的限制其中的問題就在於參數
_smm_max_size 上我們來看這個時候該參數值是多少
Sess#
SQL> select ksppinm ksppstvl ksppdesc from x$ksppi x x$ksppcv y where xindx = yindx and ksppinm in (_pga_max_size_smm_max_size);
KSPPINM KSPPSTVL KSPPDESC
_pga_max_size Maximum size of the PGA memory for one process
_smm_max_size maximum work area size in auto mode (serial)
可以看到參數_smm_max_size的值仍然是MB實際上這也是一個對 期望尺寸的限制參數這裡可以看到期望尺寸不能超過MB這時我們只要簡單的執行
Sess#
SQL> alter system set pga_aggregate_target=G;
SQL> select ksppinm ksppstvl ksppdesc from x$ksppi x x$ksppcv y where xindx = yindx and ksppinm in (_pga_max_size_smm_max_size);
KSPPINM KSPPSTVL KSPPDESC
_pga_max_size Maximum size of the PGA memory for one process
_smm_max_size maximum work area size in auto mode (serial)
我們可以看到只要設置一下pga_aggregate_target就會按照前面所說的規則重新計算並設置_smm_max_size的值該參數修改後的值為MB這個時候我們重復上面的測試
Sess#
SQL> select a* from pga_test apga_test b where rownum< order by ;
Sess#
SQL> /
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
OPTIMAL
這時我們看到期望尺寸為MB左右終於超過了MB如果我們再次將參數_smm_max_size人為的降低到MB則期望尺寸又將不能突破MB了我們來看試驗
Sess#
SQL> alter system set _smm_max_size=;
Sess#
SQL> select a* from pga_test apga_test b where rownum< order by ;
Sess#
SQL> /
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
PASS
可以看到結果正如我們所預料的由此得出我們重要的結論就是在非並行方式下期望尺寸為min(%*pga_aggregate_target%*_pga_max_size_smm_max_size)而不是很多資料上所說的不是很嚴密的min(%*pga_aggregate_target%*_pga_max_size)oracle當然是不推薦我們修改這兩個隱藏參數的
多個並發session對PGA使用情況的監控
現在我們可以來測試多個session並發時PGA的分配情況測試並發的方式有很多可以寫一個小程序循環創建多個連接然後執行上面的測試語句也可以借助一些工具來完成為了方便起見我用了一個最簡單的方式就是寫一個SQL文本再寫一個bat文件該bat文件中執行SQL文本兩個文件准備好以後將bat文件拷貝份然後選中這份一摸一樣的bat文件按回車鍵後windows XP將同時執行這個bat文件這樣就可以模擬出個session同時連接並同時執行測試語句的環境了具體這兩個文件的具體內容如下
pga_testsql
set autotrace traceonly stat;
select a* from pga_test apga_test b where rownum< order by ;
runbat
@sqlplus s cost/cost@ora @d:\test\pga_testsql
我們先將pga_aggregate_target設置為MB
Sess#
SQL> alter system set pga_aggregate_target=M;
然後同時運行個bat文件從而啟動個執行相同SQL測試語句的並發session我執行下面的語句以顯示這時正在執行的個session所消耗的PGA的總內存
Sess#
SQL> select aname sum(bvalue)// as MB
from v$statname a v$sesstat b
where astatistic# = bstatistic#
and aname like %ga %
and sid in(select sid from v$sql_workarea_active)
group by aname;
NAME MB
session pga memory
session pga memory max
session uga memory
session uga memory max
我們可以看到session pga memory max顯示出大約MB的PGA內存很明顯PGA的總容量已經超出了pga_aggregate_target(M)的限制的容量實際上這也就說明該參數只是說明oracle會盡量維護整個PGA內存不超過這個值如果實在沒有辦法也還是會突破該參數限制的
同時我們可以去查看這個時候該測試SQL語句所分配的工作區變成了多少同樣在Sess#中
SQL> @d:\pga_by_hashvaluesql
輸入 hashvalue 的值:
原值 : and ahash_value = &hashvalue
新值 : and ahash_value =
SQL_TEXT
OPERATION_TYPE POLICY Used MB
Est Opt MB Est OnePass MB LAST_EXECUTION LAST_TEMPSEG_SIZE
select a* from pga_test apga_test b where rownum< order by
SORT AUTO
PASSES
從結果中我們可以看到該SQL的工作區已經從單個session時的MB下降到了大約M我們可以看到個session總共至少需要MB(M*)的SQL工作區明顯的MB的pga_aggregate_target是肯定不能滿足需要的
其他監控並調整PGA的方法
我們監控PGA的視圖除了上面介紹到的v$sql_workarea_activev$sesstatv$sql_workarea以及v$process以外還有v$sql_workarea_histogramv$pgastat以及v$sysstat
v$sql_workarea_histogram記錄了每個范圍的SQL工作區內所執行的optimalonepassmultipass的次數如下所示
SQL> select
low_optimal_size/ Low (K)
(high_optimal_size + )/ High (K)
optimal_executions Optimal
onepass_executions Pass
multipasses_executions > Pass
from v$sql_workarea_histogram
where total_executions <> ;
結果類似如下所示我們可以看到整個系統所需要的PGA的內存大小主要集中在什麼范圍裡面
Low (K) High (K) Optimal Pass > Pass
另外我們可以將上面的查詢語句改寫一下以獲得optimalonepassmultipass執行次數的百分比很明顯optimal所占的百分比越高越好如果onepass和multipass占的百分比很高就不需要增加pga_aggregate_target的值了或者調整SQL語句以使用更少的PGA區
SQL> select
optimal_count Optimal
round(optimal_count * / total) Optimal %
onepass_count OnePass
round(onepass_count * / total) Onepass %
multipass_count MultiPass
round(multipass_count * / total) Multipass %
from (
select
sum(total_executions) total
sum(optimal_executions) optimal_count
sum (onepass_executions) onepass_count
sum (multipasses_executions) multipass_count
from v$sql_workarea_histogram
where total_executions <> )
/
Optimal Optimal % OnePass Onepass % MultiPass Multipass %
而v$pgastat則提供了有關PGA使用的整體的概括性的信息
SQL> select * from v$pgastat;
NAME VALUE UNIT
aggregate PGA target parameter bytes
aggregate PGA auto target bytes
global memory bound bytes
total PGA inuse bytes
total PGA allocated bytes
maximum PGA allocated bytes
total freeable PGA memory bytes
PGA memory freed back to OS bytes
total PGA used for auto workareas bytes
maximum PGA used for auto workareas bytes
total PGA used for manual workareas bytes
maximum PGA used for manual workareas bytes
over allocation count
bytes processed bytes
extra bytes read/written bytes
cache hit percentage percent
從結果可以看出第一行表示pga_aggregate_target設置為MPGA的一部分被用於無法動態調整的部分比如UGA中的session相關的信息等而PGA內存的剩下部分則是可以動態調整的由aggregate PGA auto target說明我們來看第二行的值就表示可以動態調整的內存數量該值不能與pga_aggregate_target設置的值差太多如果該值太小則oracle沒有足夠的內存空間來動態調整session的內存工作區其中的global memory bound表示一個工作區的最大尺寸並且oracle推薦只要該統計值低於M時就應該增加pga_aggregate_target的值另外i還提供了兩個有用的指標over allocation count和cache hit percentage如果在使用SQL工作區過程中oracle認為pga_aggregate_target過小則它自己會去多分配需要的內存則多分配的次數就累加在over allocation count指標裡該值越小越好最好為cache hit percentage則表示完全在內存裡完成的操作的字節數與所有完成的操作(包括optimalonepassmultipass)的字節數的比率如果所有的操作都是optimal類則該值為%
最後我們可以查詢v$sysstat視圖獲得optimalonepassmultipass執行的總次數
SQL> select * from v$sysstat where name like workarea executions%;
STATISTIC# NAME CLASS VALUE
workarea executions optimal
workarea executions onepass
workarea executions multipass
我們可以計算optimal次數占總次數的比率比如上例中/(++)=%該比率越大越好如果發現onepass和multipass較多則需要增加pga_aggregate_target或者調整SQL語句以使用更少的PGA區
那麼我們如何找到需要調整以使用更少的PGA的SQL語句呢?我們可以將v$sql_workarea中的記錄按照estimated_optimal_size字段由大到小的排序選出排在前幾位的hash值同時還可以選出last_execution值為n PASSES(這裡的n大於或等於)的hash值將這些hash值與v$sql關聯後找出相應的SQL語句進行調整以便使其使用更少的PGA
PGA的自動建議特性
那麼如果我們需要調整pga_aggregate_target時到底我們應該設置多大呢?oracle為了幫助我們確定這個參數的值引入了一個新的視圖v$pga_target_advice為了使用該視圖需要將初始化參數statistics_level設置為typical(缺省值)或all
SQL> select
round(pga_target_for_estimate /(*)) Target (M)
estd_pga_cache_hit_percentage Est Cache Hit %
round(estd_extra_bytes_rw/(*)) Est ReadWrite (M)
estd_overalloc_count Est OverAlloc
from v$pga_target_advice
/
Target (M) Est Cache Hit % Est ReadWrite (M) Est OverAlloc
該輸出告訴我們按照系統目前的運轉情況我們pga設置的不同值所帶來的不同效果根據該輸出我們找到能使estd_overalloc_count為的最小pga_aggregate_target的值從這裡可以看出是M注意隨著我們增加pga的尺寸estd_pga_cache_hit_percentage不斷增加同時estd_extra_bytes_rw(表示onepassmultipass讀寫的字節數)不斷減小從上面的結果我們可以知道將pga_aggregate_target設置為MB是最合理的因為即便將其設置為MB命中率也不會有所提高
同時我們知道v$tempstat裡記錄了讀寫臨時表空間的數據塊數量以及所花費的時間這樣我們就可以結合v$pga_target_advice和v$tempstat這兩個視圖可以得到每一種估計PGA值下的響應時間大致是多少從而可以換一個角度來顯示PGA的建議值
SQL> SELECT PGA Aggregate Target component
ROUND (pga_target_for_estimate / ) target_size
estd_pga_cache_hit_percentage cache_hit_ratio
ROUND ( ( ( estd_extra_bytes_rw / DECODE ((bBLOCKSIZE * iavg_blocks_per_io)
(bBLOCKSIZE * iavg_blocks_per_io)))* iiotime)/ ) response_time(sec)
FROM v$pga_target_advice
(SELECT /*+AVG TIME TO DO AN IO TO TEMP TABLESPACE*/
AVG ( (readtim + writetim) /
DECODE ((phyrds + phywrts) (phyrds + phywrts)) ) iotime
AVG ( (phyblkrd + phyblkwrt)/
DECODE ((phyrds + phywrts) (phyrds + phywrts))) avg_blocks_per_io
FROM v$tempstat) i
(SELECT /* temp ts block size */ VALUE BLOCKSIZE
FROM v$parameter WHERE NAME = db_block_size) b;
COMPONENT TARGET_SIZE CACHE_HIT_RATIO response_time(sec)
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
PGA Aggregate Target
注意每次我們調整了pga_aggregate_target參數以後都應該在系統運行一兩天以後檢查視圖v$sysstatv$pgastatv$pga_target_advice以確定修改的值是否滿足系統的需要
From:http://tw.wingwit.com/Article/program/Oracle/201311/17537.html