隨著數據庫技術的不斷發展及數據庫管理系統的廣泛應用
數據庫中存儲的數據量急劇增大
在大量的數據背後隱藏著許多重要的信息
如果能把這些信息從數據庫中抽取出來
將為公司創造很多潛在的利潤
而這種從海量數據庫中挖掘信息的技術
就稱之為數據挖掘
數據挖掘工具能夠對將來的趨勢和行為進行預測
從而很好地支持人們的決策
比如
經過對公司整個數據庫系統的分析
數據挖掘工具可以回答諸如
哪個客戶對我們公司的郵件推銷活動最有可能作出反應
為什麼
等類似的問題
有些數據挖掘工具還能夠解決一些很消耗人工時間的傳統問題
因為它們能夠快速地浏覽整個數據庫
找出一些專家們不易察覺的極有用的信息
下文將對數據挖掘的基本技術作一個簡單的介紹
數據挖掘的基礎
數據挖掘技術是人們長期對數據庫技術進行研究和開發的結果
起初各種商業數據是存儲在計算機的數據庫中的
然後發展到可對數據庫進行查詢和訪問
進而發展到對數據庫的即時遍歷
數據挖掘使數據庫技術進入了一個更高級的階段
它不僅能對過去的數據進行查詢和遍歷
並且能夠找出過去數據之間的潛在聯系
從而促進信息的傳遞
現在數據挖掘技術在商業應用中已經可以馬上投入使用
因為對這種技術進行支持的三種基礎技術已經發展成熟
他們是
海量數據搜集
強大的多處理器計算機
數據挖掘算法
商業數據庫現在正在以一個空前的速度增長
並且數據倉庫正在廣泛地應用於各種行業
對計算機硬件性能越來越高的要求
也可以用現在已經成熟的並行多處理機的技術來滿足
另外數據挖掘算法經過了這
多年的發展也已經成為一種成熟
穩定
且易於理解和操作的技術
從商業數據到商業信息的進化過程中
每一步前進都是建立在上一步的基礎上的
見下表
表中我們可以看到
第四步進化是革命性的
因為從用戶的角度來看
這一階段的數據庫技術已經可以快速地回答商業上的很多問題了
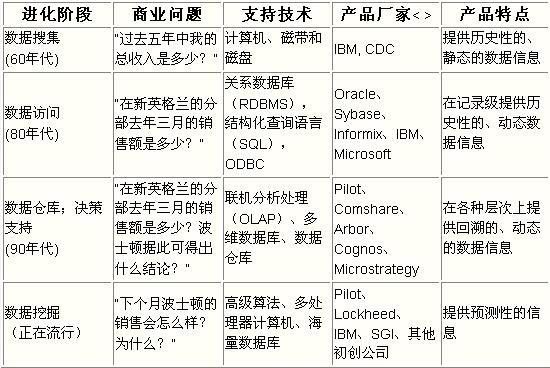
表一
數據挖掘的進化歷程
數據挖掘的核心模塊技術歷經了數十年的發展
其中包括數理統計
人工智能
機器學習
今天
這些成熟的技術
加上高性能的關系數據庫引擎以及廣泛的數據集成
讓數據挖掘技術在當前的數據倉庫環境中進入了實用的階段
數據挖掘的范圍
數據挖掘
這個名字來源於它有點類似於在山脈中挖掘有價值的礦藏
在商業應用裡
它就表現為在大型數據庫裡面搜索有價值的商業信息
這兩種過程都需要對巨量的材料進行詳細地過濾
並且需要智能且精確地定位潛在價值的所在
對於給定了大小的數據庫
數據挖掘技術可以用它如下的超能力產生巨大的商業機會
自動趨勢預測
數據挖掘能自動在大型數據庫裡面找尋潛在的預測信息
傳統上需要很多專家來進行分析的問題
現在可以快速而直接地從數據中間找到答案
一個典型的利用數據挖掘進行預測的例子就是目標營銷
數據挖掘工具可以根據過去郵件推銷中的大量數據找出其中最有可能對將來的郵件推銷作出反應的客戶
自動探測以前未發現的模式
數據挖掘工具掃描整個數據庫並辨認出那些隱藏著的模式
比如通過分析零售數據來辨別出表面上看起來沒聯系的產品
實際上有很多情況下是一起被售出的情況
數據挖掘技術可以讓現有的軟件和硬件更加自動化
並且可以在升級的或者新開發的平台上執行
當數據挖掘工具運行於高性能的並行處理系統上的時候
它能在數分鐘內分析一個超大型的數據庫
這種更快的處理速度意味著用戶有更多的機會來分析數據
讓分析的結果更加准確可靠
並且易於理解
數據庫可以由此拓展深度和廣度
深度上
允許有更多的列存在
以往
在進行較復雜的數據分析時
專家們限於時間因素
不得不對參加運算的變量數量加以限制
但是那些被丟棄而沒有參加運算的變量有可能包含著另一些不為人知的有用信息
現在
高性能的數據挖掘工具讓用戶對數據庫能進行通盤的深度編歷
並且任何可能參選的變量都被考慮進去
再不需要選擇變量的子集來進行運算了
廣度上
允許有更多的行存在
更大的樣本讓產生錯誤和變化的概率降低
這樣用戶就能更加精確地推導出一些雖小但頗為重要的結論
最近
Gartner Group的一次高級技術調查將數據挖掘和人工智能列為
未來三到五年內將對工業產生深遠影響的五大關鍵技術
之首
並且還將並行處理體系和數據挖掘列為未來五年內投資焦點的十大新興技術前兩位
根據最近Gartner的HPC研究表明
隨著數據捕獲
傳輸和存儲技術的快速發展
大型系統用戶將更多地需要采用新技術來挖掘市場以外的價值
采用更為廣闊的並行處理系統來創建新的商業增長點
在數據挖掘中最常用的技術有
人工神經網絡
仿照生理神經網絡結構的非線形預測模型
通過學習進行模式識別
決策樹
代表著決策集的樹形結構
遺傳算法
基於進化理論
並采用遺傳結合
遺傳變異
以及自然選擇等設計方法的優化技術
近鄰算法
將數據集合中每一個記錄進行分類的方法
規則推導
從統計意義上對數據中的
如果
那麼
規則進行尋找和推導
采用上述技術的某些專門的分析工具已經發展了大約十年的歷史
不過這些工具所面對的數據量通常較小
而現在這些技術已經被直接集成到許多大型的工業標准的數據倉庫和聯機分析系統中去了
數據挖掘是如何工作的
數據挖掘工具是怎樣准確地告訴你那些隱藏在數據庫深處的重要信息的呢?它們又是如何作出預測的?答案就是建模
建模實際上就是在你知道結果的情況下建立起一種模型
並且把這種模型應用到你所不知道的那種情況中
比如說
如果你想要在大海上去尋找一艘古老的西班牙沉船
也許你首先想到的就是去找找過去發現這些寶藏的時間和地點有哪些
那麼
經過調查你發現這些沉船大部分都是在百慕大海區被發現
並且那個海區有著某種特征的洋流
以及那個時代的航線也有一定的特征可尋
在這眾多的類似特征中
你將它們抽象並概括為一個普適的模型
利用這個模型
你就很有希望在具有大量相同特征的另外一個地點發現一件不為人知的寶藏
當然
在數據挖掘技術甚至計算機出現以前
這種建模抽象的方法就已經廣泛地被人們所使用
在計算機中的建模和以前的建模方法並無很大不同
主要的差異在於計算機能處理的信息量比起以前來更加龐大
計算機中能夠存儲已知了結果的大量不同情況
然後由數據挖掘工具從這些大量的信息裡面披沙揀金
將能夠產生模型的信息提取出來
一當模型建立好了之後
就可以應用在那些情形相似但結果尚未知的判斷中了
比如
現在假設你是一個電信公司的營銷主任
公司想發展一些新的長途電話用戶
那麼你是不是會漫無目的地到街上去散發廣告呢?——就象漫無目的地在海上去尋寶一樣
其實
比起漫無目的地去進行宣傳來
利用你以前的商業經驗來有目的地去拉攏客戶會產生高得多的效率
作為一個營銷主任
你對客戶的很多信息都可以了解得一清二楚
年齡
性別
信用記錄以及長途電話使用狀況
從好的一方面來看
掌握了這些客戶的信息其實就是掌握了很多潛在的用戶的同樣的信息
問題在於你還不一定了解他們的長途電話使用情況(因為他們的長途電話也許是通過的另一個電信公司)
現在你的主要精力就集中在用戶中誰有比較多的長途電話上
通過下面這個表格
我們可以從數據庫裡面抽象某些變量
建立起一個可以對此進行分類營銷的模型

表二
數據挖掘應用於分類營銷
根據我們創建的從一般信息到私有信息的計算模型
我們可以得出表二右下方表格中的信息
比如
一個電信公司的簡化模型可以是
年薪
萬美圓以上的
%的客戶
每個月長話費
美圓以上
根據這個模型
我們就能應用這些數據來推斷出公司現在尚不能明確的私有信息
這樣
新客戶群體就可以大體確定出來了
小型市場的試銷數據對於這樣的模型來說顯得極為有用
因為小范圍內試銷數據的挖掘
能夠為全部市場的分類銷售打下一個良好的基礎
表三則描述了另外一樣數據挖掘的普遍應用
預測

表三
數據挖掘應用於預測
數據挖掘的體系結構
現有很多數據挖掘工具是獨立於數據倉庫以外的
它們需要獨立地輸入輸出數據
以及進行相對獨立的數據分析
為了最大限度地發揮數據挖掘工具的潛力
它們必須象很多商業分析軟件一樣
緊密地和數據倉庫集成起來
這樣
在人們對參數和分析深度進行變化的時候
高集成度就能大大地簡化數據挖掘過程
下圖顯示了一個大型數據庫中的高級分析過程
集成後的數據挖掘體系
應用數據挖掘技術
較為理想的起點就是從一個數據倉庫開始
這個數據倉庫裡面應保存著所有客戶的合同信息
並且還應有相應的市場競爭對手的相關數據
這樣的數據庫可以是各種市場上的數據庫
Sybase
Oracle
Redbrick
和其他等等
並且可以針對其中的數據進行速度上和靈活性上的優化
聯機分析系統OLAP服務器可以使一個十分復雜的最終用戶商業模型應用於數據倉庫中
數據庫的多維結構可以讓用戶從不同角度
——比如產品分類
地域分類
或者其他關鍵角度——來分析和觀察他們的生意運營狀況
數據挖掘服務器在這種情況下必須和聯機分析服務器
以及數據倉庫緊密地集成起來
這樣就可以直接跟蹤數據和並輔助用戶快速作出商業決策
並且用戶還可以在更新數據的時候不斷發現
From:http://tw.wingwit.com/Article/os/xtgl/201311/9368.html