第一章 數據挖掘介紹
什麼是數據挖掘
數據挖掘(Data Mining)是一個利用各種分析工具在海量數據中發現模型和數據之間關系的過程
這些模型和關系可以被企業用來分析風險
進行預測
數據挖掘是通過仔細分析大量數據來揭示有意義的新的關系
模式和趨勢的過程
它使用模式認知技術
統計技術和數學技術
(Gartner Group)
數據挖掘是一個從大型數據庫中提取以前不知道的可操作性信息的知識挖掘過程
(Aaron Zornes
The META Group)
數據挖掘能夠幫助企業降低成本
減少風險
提高資金回報率
現在很多公司開始采用數據挖掘技術來判斷哪些是最有價值客戶
重整產品推廣策略
以用最小的花費得到最好的銷售
電信行業和銀行業較先使用數據挖掘
電信公司使用數據挖掘檢測話費欺詐行為
銀行使用數據挖掘檢測信用卡欺詐行為
數據挖掘模型建立完成後
進行驗證和評價非常必要
比如用市場調查得到的客戶數據做了一個模型
來預測哪些客戶群會對新產品感興趣
通常情況下還不能用這個模型直接指導行動
更穩妥的做法是
先對一小部分客戶做一個實際的測試
得到市場的實際反應情況
然後再大規模的采取市場推廣行動
數據挖掘幫助分析師和決策人員更深入
更容易的分析數據
為了保證數據挖掘結果的價值
用戶必須非常了解自己的數據
並且了解數據挖掘工具是如何工作的
了解不同的技術和算法對模型的准確度和模型生成速度的影響
大部分情況下
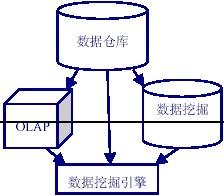
數據挖掘的分析數據源可以是數據倉庫或數據挖掘數據集市
數據挖掘工具訪問數據倉庫進行數據挖掘有許多好處
因為導入到數據倉庫的數據已經經過了大量的數據清理和轉換工作
減少數據挖掘的數據清理過程
圖
數據挖掘支持多數據源
在實施數據挖掘之前
需要制定實施步驟
有了好的計劃才能保證數據挖掘順利實施並取得成功
數據挖掘軟件供應商提供了一些數據挖掘的過程模型
用來指導用戶實施數據挖掘
比如SPSS的
A――評估(Assess)
訪問(Access)
分析(Analyze)
行動(Act)和自動化(Automate)
以及SAS的SEMMA――采樣(Sample)
探索(Explore)
修正(Modify)
建模(Model)和評估(Assess)
數據挖掘與OLAP
數據挖掘和OLAP是兩種完全不同的工具
他們的用途不同
基於的技術也大相徑庭
OLAP是驗證式的工具
告訴用戶下一步會怎麼樣(What next)
如果采取這樣的措施又會怎麼樣(What if)
OLAP分析過程是一個演繹推理的過程
用戶首先建立一個假設
然後用OLAP工具浏覽數據來驗證假設
如果一個分析涉及到的變量達到幾十或上百個
那麼用OLAP手動分析驗證這些假設將是一件非常困難的事情
數據挖掘與OLAP不同的地方是
數據挖掘不是用於驗證某個假定的模型的正確性
而是在數據庫中自己尋找模型
數據挖掘過程是一個歸納的過程
如果一個分析師打算用數據挖掘工具分析移動電話用戶的欠費風險
數據挖掘工具可能會幫助分析師發現一些從來沒有想過的影響因素
數據挖掘比OLAP更自動化
更深入
分析結果更難被理解
數據挖掘和OLAP具有一定的互補性
在利用數據挖掘工具挖掘出來的結論采取行動之前
你也許要用OLAP驗證一下如果采取這樣的行動會給企業帶來什麼樣的影響
將OLAP和DataMining技術結合起來形成了一個新的體系OLAM(On
Line Analytical Mining)
在OLAP中挖掘多層
多維的關聯規則是一個很有效果的過程
可以挖掘到一些新的規則
數據挖掘與CRM
數據挖掘能自動從龐大的數據中找到預測客戶購買行為的模式
進行數據挖掘後
把結果輸入到促銷活動管理軟件中
可以大大提高促銷的效果
數據挖掘輔助基於數據庫的銷售
數據挖掘能幫助銷售人員更准確地定位推銷活動
並使活動緊密結合現有客戶和潛在客戶的需求
願望和狀態
數據挖掘和CRM結合
通過數據挖掘優化CRM流程
可以用來留住客戶
提高活動的響應率
數據挖掘利用數據庫的信息創建模型和預測客戶行為
在使用數據挖掘給客戶評分後
這些分數就可以用來為推銷活動選擇最適合的客戶群
數據挖掘得出的可能流失客戶名單
通過呼叫中心對客戶進行關懷訪問
爭取留住客戶
從而達到企業的長期利潤最大化的目的
數據挖掘可以增加客戶在整個生命周期裡的價值
通過追蹤響應率和遵照客戶行為變化的規則
可以評測市場推廣活動的利潤率和投資回報率
我們希望CRM系統提供
封閉循環的推銷
不僅預測推銷效果
執行推銷活動
而且
封閉循環
能夠衡量活動的結果
系統衡量推銷活動的效果
在下一個循環中
就可以采取措施提高有效性
數據挖掘
AI與統計
統計學和數據挖掘有同樣的目標
發現數據中的結構
所以有人認為數據挖掘是統計學的分支
這是一個不切合實際的結論
有兩個原因說明這個問題
一是數據挖掘更多的是應用其它領域的思想
工具和方法
尤其是數據庫技術和機器學習等計算機學科分支
二是由於統計學的數學背景和追求精確的方法
在采用一個方法之前先要進行充分的證明
而不是類似計算機科學和機器學習那樣注重於經驗
神經元網絡
遺傳算法和機器學習等知識發現技術
在足夠多的數據和計算能力下
可以自動完成許多有價值的計算
關於數據挖掘和知識發現的關系
有很多人認為數據挖掘是知識發現過程的一個步驟
一些人則把數據挖掘和知識發現等同起來
數據挖掘利用統計和人工智能的技術
把這些高深復雜的技術封裝起來
使用戶不用掌握這些技術也能完成同樣的功能
從而更加專注於自己所要解決的問題
第二章數據挖掘模型和算法
數據挖掘軟件使用的算法基本上都是成熟的
公開的算法
有一些公司采用自己研發的未公開的算法
大部分算法都不是專為解決某個問題而設計的
算法之間沒有互斥性
不能認為一個問題非要采用某種算法
也不存在所謂最好的算法
一般通過試驗來選取合適的算法
一
關聯分析
關聯分析挖掘數據中項集之間有意義的關聯或相關聯系
關聯分析是尋找數據庫中數值的相關性
常用的技術是關聯規則和序列模式
從大量商業數據中發現有意義的關聯關系
可以幫助商業決策的制定
如交叉銷售和優惠促銷行動等
典型的應用如超市使用關聯分析設計商品的擺放位置
方便顧客購物
表達某一特定關聯出現的頻率在關聯規則中稱為支持度
當情況一出現時
發生情況二的概率在關聯規則中稱為可信度
比如在
萬個移動通信用戶中
有
萬用戶使用手機銀行業務
萬用戶同時使用手機銀行和移動秘書業務
則同時使用兩種業務的支持度為
/
=
%
使用手機銀行業務的用戶
會選擇移動秘書業務的可信度為
/
=
%
關聯分析得到的模式需要其它數據驗證其正確性
並進行必要的試驗
來保證利用歷史數據得到的規律有效的應用於未來的環境
比如
設計超市商品擺放在貨架的位置
把相關性強的商品擺放在一起
可能會導致這樣的情況發生
顧客非常容易的找到需要的商品
就不會去考慮哪些不在購買計劃內的商品
所以
在實施之前一定要經過充分的分析和試驗
Apriori算法是挖掘布爾關聯規則最有影響的算法
但Apriori算法遞推的過程
要求多次的數據庫掃描
將引起很大的I/O負載
Agrawal等引入了修剪技術改進算法的性能
采用基於采樣的方法也可以顯著地減少了I/O負載
在數據庫中選取隨機樣本S
在樣本S中搜索頻集
再用另一個樣本數據驗證結果
分類和預測
分類就是對一個事件或一組對象進行歸類
可以用分類模型分析已有的數據
還可以用分類模型來預測未來
分類和預測是兩類主要的預測問題
預測離散數據通常稱為分類
預測連續數據通常稱為預測
分類算法通過分析已知的分類信息得到一個預測模型
用於建立模型的分類數據稱為訓練集
訓練集也可以是通過實驗得到的數據
比如從數據庫中提取出一個客戶名單列表
向這些客戶發送新產品的介紹資料
然後收集對此做出回應的客戶資料
用這些記錄建立一個預測模型
預測哪類用戶會對新產品感興趣
最後把這個模型應用於新產品的推廣
決策樹是一種典型的分類算法
可以得到類似在什麼條件下會得到什麼結果的規則
比如
建立顧客決策樹模型
進行市場細分
找出最有可能對促銷宣傳感興趣的客戶群
沿著決策樹從上到下遍歷的過程中
在每個節點都會遇到一個問題
對每個節點上問題的不同條件得到不同的分支子樹
最後到達葉子節點
生成決策樹的過程是不斷把數據進行切分的過程
常用的決策數算法有ID
C
和CART等
決策樹的優點是生成容易理解的規則
如果建立一個包含幾百個屬性的決策樹
雖然看起來很復雜
但每一條從根結點到葉子節點的路徑所描述的含義還是可以理解的
再者
決策樹算法的計算量相對來說不是很大
並且擅長處理非數值型數據
使用決策樹算法也要注意其局限性
決策樹對連續性的字段比較難預測
對有時間順序的數據需要很多預處理
決策樹的明確性可能會誤導使用者
因為每個節點對應分割的定義都是明確不含糊的
但在實際應用中會有問題
比如為什麼認為年齡為
歲的用戶通信話費欺詐風險高於
歲的用戶?
聚類分析
聚類就是將數據分組成多個類或簇
同一個簇中的對象之間具有較高的相似度
與分類不同的是
在進行聚集分析之前不知道要把數據分成幾組
也不知道怎麼分
因此在聚類分析之後要有對業務很熟悉的分析師來解釋聚類結果的意義
聚類能夠幫助市場分析人員從客戶數據庫中發現不同的客戶群
並用購買模式來描述各個客戶群的特征
神經網絡(Artificial Neural Network
簡稱A
N
N
)是常用的聚集算法
應
From:http://tw.wingwit.com/Article/os/xtgl/201311/8835.html